Nền tảng đám mây ZStack
Triển khai một máy chủ với đầy đủ tính năng, miễn phí trong một năm

Tài liệu và công cụ sản phẩm toàn diện

Đề cao giá trị của Khách hàng là trên hết và sứ mệnh Phục vụ Khách hàng, ZStack tận tâm cung cấp các dịch vụ an toàn và ổn định cho khách hàng.

Để giáo dục các đối tác của ZStack và những cá nhân quan tâm về điện toán đám mây và trau dồi tài năng về điện toán đám mây.

ZStack cung cấp cơ sở hạ tầng đám mây sáng tạo cho mười ngành công nghiệp chính

Thông qua ba phần chính, hàng chục ngàn từ và hơn 10 khách hàng đại diện toàn cầu
Trong hệ sinh thái nền tảng đám mây, API là mối liên kết cốt lõi giữa khả năng của sản phẩm và nhà phát triển. Tài liệu API chính xác, đầy đủ và cập nhật ảnh hưởng trực tiếp đến hiệu quả tích hợp và trải nghiệm người dùng của nhà phát triển. Tuy nhiên, khi khả năng của nền tảng tiếp tục phát triển, bề mặt API tiếp tục mở rộng và áp lực bảo trì tài liệu cũng tăng theo. Mỗi lần bổ sung, thay đổi hoặc ngừng sử dụng API đều yêu cầu cập nhật đồng bộ hóa hướng dẫn phát triển, tài liệu tham khảo CLI và API Explorer. Khi một số lượng lớn giao diện tiếp tục thay đổi, cách giữ tài liệu nhất quán với mã, thống nhất nhiều định dạng xuất bản cũng như cân bằng hiệu quả và chất lượng song ngữ đã trở thành thách thức cốt lõi của kỹ thuật tài liệu API.
Bài viết này dựa trên các phương pháp thực hành tài liệu API của ZStack ZCF (ZStack Cloud Foundation). Nó cung cấp phần giới thiệu chuyên sâu về việc triển khai tự động hóa tài liệu API từ đầu đến cuối từ quan điểm của kiến trúc xuất bản đa kênh, phương pháp thiết kế dựa trên tác nhân AI cũng như các thách thức và giải pháp cốt lõi trong triển khai kỹ thuật.
ZStack Cloud Foundation (ZCF) là giải pháp đám mây riêng tích hợp sâu các khả năng trên nhiều sản phẩm. Thông qua một cổng thông tin hợp nhất, O&M hợp nhất và quản lý tài nguyên máy tính hợp nhất, nó mang lại trải nghiệm quản lý toàn diện thân thiện và thuận tiện. ZCF cung cấp một bộ API RESTful phong phú bao gồm tính toán, vận hành, giám sát, cảnh báo và các lĩnh vực khác.
Xung quanh API ZCF, ZStack đã xây dựng một hệ thống xuất bản tài liệu đa kênh, đa định dạng để đáp ứng nhu cầu của người dùng trong các tình huống khác nhau:
hướng dẫn sử dụng PDF: Đối với các kịch bản giao hàng trang trọng, phiên bản song ngữ tiếng Trung và tiếng Anh được cung cấp. Chúng bao gồm các tham số yêu cầu, trường phản hồi, mẫu Curl và mẫu mã SDK cho từng API, khiến chúng phù hợp cho việc tư vấn ngoại tuyến và lưu trữ dự án.
Tài liệu trực tuyến HTML5: Đối với các tình huống phát triển hàng ngày, nhà phát triển có thể tìm kiếm và duyệt bất kỳ lúc nào trong trình duyệt để nhanh chóng tìm thấy API cần thiết.
Trình khám phá API: Đối với các kịch bản phát triển tương tác, API Explorer hiện đang hoạt động dưới dạng phần tham chiếu API trong Trung tâm Tài liệu ZSite. Nó cung cấp tìm kiếm toàn văn bản, điều hướng được phân loại, mẫu mã đa ngôn ngữ và các điểm đánh dấu thay đổi phiên bản (Đã thêm, Đã sửa đổi, Đã xóa), giúp các nhà phát triển hiểu được quá trình phát triển API một cách trực quan.
Hướng dẫn tham khảo CLI: Đối với các kịch bản O&M và tự động hóa, nó cung cấp lệnh gọi dòng lệnh và mô tả tham số tương ứng với từng API.
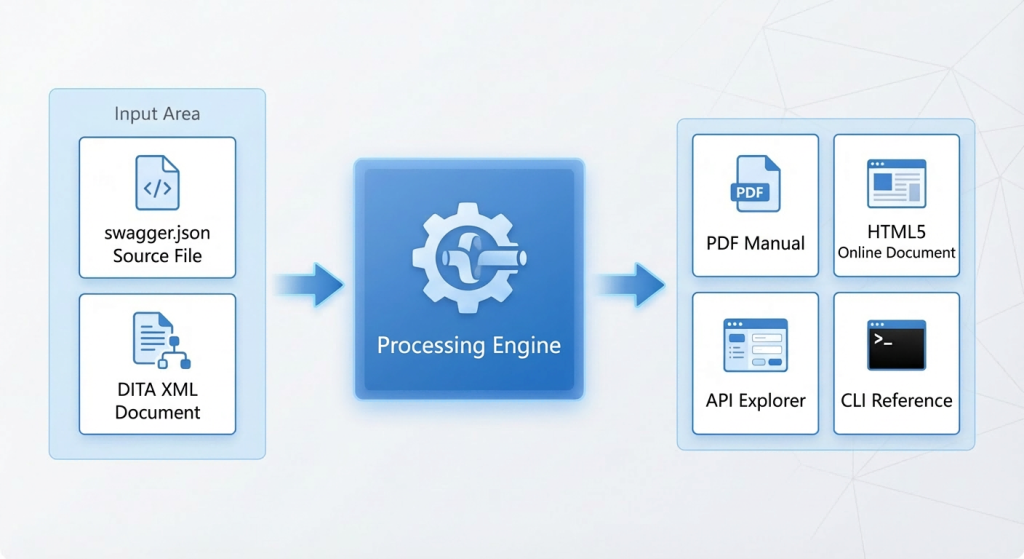
Hình 1. Kiến trúc xuất bản đa kênh của tài liệu API ZCF
Hệ thống xuất bản này được củng cố bởi hai nguồn dữ liệu. Đầu tiên là tệp đặc tả Swagger (swagger.json), tệp này được nhóm phát triển phụ trợ tạo tự động cùng với mã. Đây là nguồn sự thật duy nhất cho các định nghĩa API và chứa siêu dữ liệu có cấu trúc như đường dẫn, phương thức, cấu trúc tham số và mô hình phản hồi của từng API. Thứ hai là tài liệu DITA có cấu trúc, đóng vai trò là nền tảng nội dung của hệ thống tài liệu ZStack. Nó tổ chức nội dung văn bản bằng XML và được biên dịch thành PDF, HTML5 và các định dạng đích khác thông qua chuỗi công cụ DITA-OT.
Trước khi tự động hóa được giới thiệu, các bản cập nhật cho tài liệu API ZStack chủ yếu dựa vào công việc thủ công. Mô hình này có bốn điểm yếu nổi bật:
Điểm nghẽn hiệu quả: Một lần lặp lại một phiên bản có thể liên quan đến những thay đổi đối với hàng chục API. Chỉ riêng việc viết và dịch DITA thường mất từ một đến hai tuần hoặc thậm chí lâu hơn, khiến việc theo kịp nhịp phát hành tần số cao trở nên khó khăn.
Rủi ro nhất quán: Tài liệu phụ thuộc vào tài liệu tham khảo Markdown do nhóm phụ trợ cung cấp. Nếu chúng không nhất quán với mã thực tế, các lỗi tài liệu có thể dễ dàng xuất hiện, khiến các nhà phát triển có thông tin mâu thuẫn.
biến động chất lượng: Viết tay tùy thuộc vào kinh nghiệm cá nhân. Tài liệu do các kỹ sư khác nhau tạo ra khác nhau đáng kể về quy ước cấu trúc, cách sử dụng thuật ngữ và chất lượng dịch thuật, đồng thời thiếu cơ chế bảo vệ chất lượng thống nhất.
Thiếu khả năng sử dụng tương tác là một lỗ hổng trước đây: quy trình công việc ban đầu không bao gồm các khả năng của API Explorer, do đó không có trải nghiệm tương tác trực tuyến thống nhất; với Trung tâm Tài liệu ZSite và API Explorer hiện đang hoạt động, khả năng này có sẵn thông qua cổng tài liệu trực tuyến.
Với sự phát triển không ngừng của hàng trăm API và yêu cầu khắt khe về xuất bản đa kênh đồng bộ, mô hình thủ công truyền thống không còn bền vững nữa. Về cơ bản, cách kết nối chuỗi tài liệu đầy đủ từ Swagger với người dùng cuối và tự động cập nhật tài liệu bất cứ khi nào thay đổi API trở thành một thách thức kỹ thuật cấp bách.
Để đối phó với những thách thức này, ZStack đã xem xét lại quy trình sản xuất tài liệu API từ góc độ của các tác nhân AI: phân tách các hoạt động thủ công của các kỹ sư tài liệu thành các giai đoạn tự động có thể điều phối, có thể kiểm chứng và tái tạo, tất cả đều được lên lịch và thực thi bởi các tác nhân AI. Không giống như CI/CD truyền thống, các tác nhân AI có khả năng hiểu ngữ nghĩa. Họ có thể diễn giải các thông số kỹ thuật của Swagger và DITA, quyết định nên vượt qua hay chặn cổng chất lượng và cung cấp phản hồi bằng ngôn ngữ tự nhiên về việc thực hiện từng giai đoạn.
Kiến trúc tổng thể áp dụng thiết kế quy trình sáu giai đoạn, sử dụng các thay đổi Git đối với swagger.json trong kho lưu trữ mã phụ trợ làm tín hiệu điều khiển để hoàn thành quy trình tự động hóa vòng kín từ phát hiện khác biệt đến phân phối cho người dùng cuối.
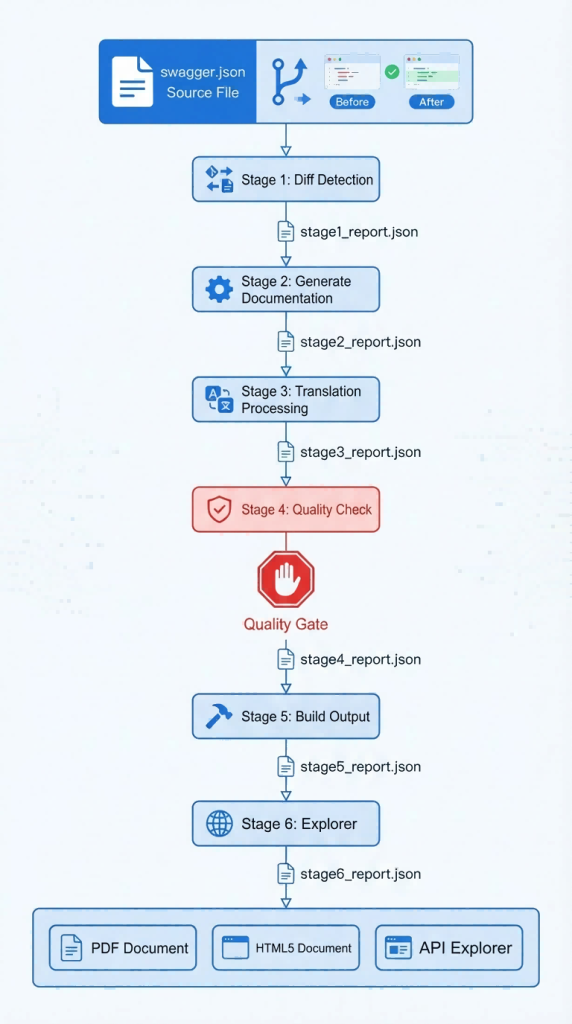
Hình 2. Kiến trúc đường ống tự động hóa từ đầu đến cuối
Giai đoạn 1: Phát hiện khác biệt và tạo nội dung (Tạo)
Quy trình bắt đầu với việc phát hiện thay đổi Swagger. Khi một cam kết Git cập nhật swagger.json trong kho lưu trữ mã phụ trợ, hệ thống sẽ tự động truy xuất các phiên bản trước và sau khi thay đổi và thực hiện so sánh ngữ nghĩa sâu sắc. Bằng cách giải quyết đệ quy các tham chiếu $ref và các thành phần allOf, nó xác định chính xác xem mỗi hoạt động API được thêm, sửa đổi hay xóa và đưa ra danh sách thay đổi có cấu trúc. Sau đó, nó áp dụng các chiến lược khác nhau cho từng loại thay đổi: đối với các hoạt động bổ sung, nó tự động tạo các chủ đề DITA hoàn chỉnh, bao gồm các bảng tham số yêu cầu, bảng trường phản hồi, mẫu Curl và mẫu mã SDK, đồng thời chèn chúng vào danh mục Ditamap tiếng Trung và tiếng Anh; đối với các hoạt động được sửa đổi, nó định vị các tệp hiện có và tạo lại nội dung tại chỗ; đối với các hoạt động đã xóa, nó sẽ dọn sạch đồng bộ các tệp và tham chiếu danh mục.
Giai đoạn 2: Xác thực mô phỏng tĩnh (Thử nghiệm)
Ở giai đoạn này, các tệp DITA được tạo sẽ trải qua quá trình xác thực chéo giữa tài liệu và thông số kỹ thuật. Hệ thống phân tích siêu dữ liệu API từ các tệp nguồn DITA và so sánh nó với các định nghĩa ban đầu trong đặc tả Swagger trên bảy thứ nguyên: tên API, đường dẫn yêu cầu, tham số bắt buộc, trường nội dung yêu cầu, mẫu Curl, phản hồi mẫu và mẫu SDK. Giai đoạn này không yêu cầu bắt đầu dịch vụ phụ trợ. Nó được hoàn thành hoàn toàn thông qua phân tích tĩnh và có thể trả về kết quả xác thực cho từng API trong vòng vài giây.
Giai đoạn 3: Dịch song ngữ dựa trên quy tắc (Dịch)
Ở giai đoạn này, các tệp DITA tiếng Trung đã được xác thực sẽ được dịch sang phiên bản tiếng Anh. Do tài liệu API do máy tạo có cấu trúc cao và sử dụng từ vựng đóng nên hệ thống áp dụng chiến lược dịch thuật xác định hoàn toàn dựa trên quy tắc. Nó chuyển đổi tiếng Trung sang tiếng Anh thông qua quy trình thay thế chuỗi chín bước mà không cần gọi bất kỳ mô hình ngôn ngữ lớn nào. Sau khi dịch, hệ thống sẽ tự động quét các tệp đầu ra để tìm các ký tự tiếng Trung chưa được dịch như một biện pháp kiểm tra bảo vệ để đảm bảo bản dịch hoàn chỉnh.
Giai đoạn 4: Cổng chất lượng (Ôn tập)
Cổng chất lượng là điểm kiểm tra cốt lõi của toàn bộ đường ống và là cổng cứng duy nhất. Bất kỳ phát hiện đánh giá nào ở cấp độ lỗi sẽ chặn quy trình và ngăn nội dung có vấn đề xâm nhập vào các giai đoạn biên soạn và xuất bản tiếp theo. Hệ thống áp dụng 22 quy tắc chất lượng được mã hóa cho cả tệp tiếng Trung và tiếng Anh, bao gồm sáu loại kiểm tra: tính đầy đủ của cấu trúc tài liệu (S), độ chính xác của nội dung API (A), tuân thủ tiêu đề (T), tính nhất quán của tiêu đề (H), tính chính xác của thẻ nội tuyến (L) và chất lượng dịch (Q). Mỗi quy tắc được triển khai dưới dạng một chức năng thuần túy lấy nội dung tệp và mã định danh ngôn ngữ làm kết quả có cấu trúc đầu vào và đầu ra, đảm bảo rằng các tiêu chuẩn chất lượng có thể theo dõi, tái tạo và độc lập với từng người đánh giá.
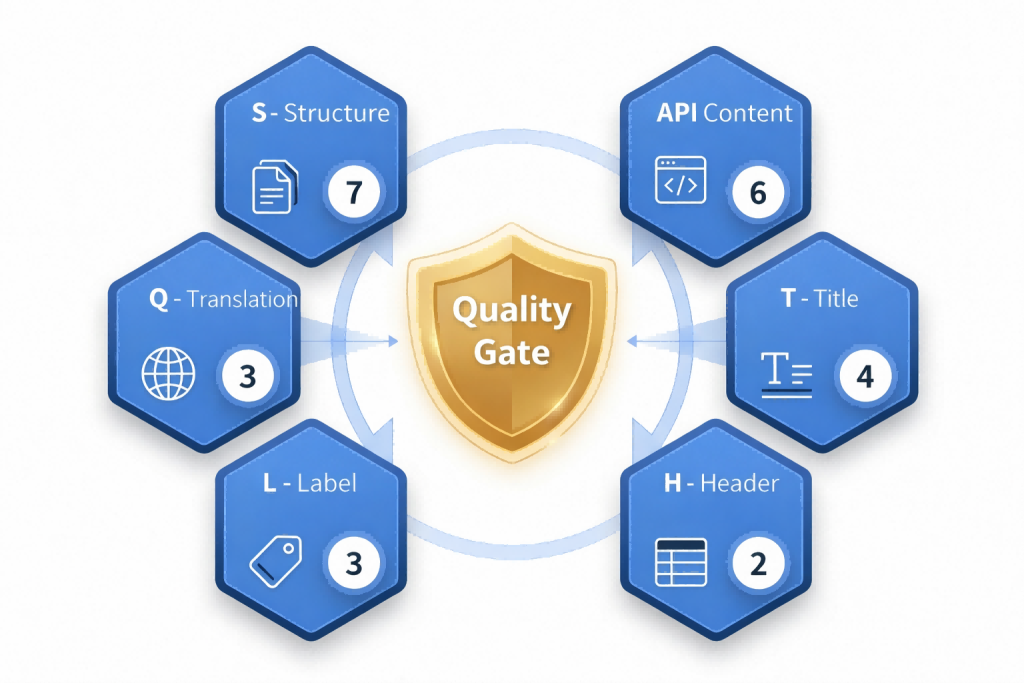
Hình 3. Sáu hạng mục kiểm tra cổng chất lượng
Giai đoạn 5: Xây dựng và xuất bản song ngữ (Build)
Sau khi vượt qua cổng chất lượng, hệ thống sẽ biên dịch Ditamaps tiếng Trung và tiếng Anh một cách riêng biệt và sử dụng chuỗi công cụ DITA-OT để tạo hướng dẫn phát triển PDF. Nhật ký bản dựng được phát trực tuyến theo thời gian thực trong quá trình biên dịch và các kết quả có cấu trúc được trích xuất sau khi hoàn thành, bao gồm thành công hay thất bại, lỗi chặn, thông tin cảnh báo và đường dẫn tạo tác để tổng đài viên diễn giải và đưa ra quyết định.
Giai đoạn 6: Đồng bộ hóa API Explorer (Explorer)
Ở giai đoạn cuối, các thay đổi được đồng bộ hóa với nền tảng API Explorer hiện đang hoạt động. API Explorer hiện phục vụ người dùng như một phần của Trung tâm Tài liệu ZSite. Lối vào: https://docs.zstack-cloud.com/docs/api-explorer/en. Dựa trên các điểm khác biệt của Swagger, hệ thống tạo ra một bảng kê khai thay đổi, sau đó xây dựng lại toàn bộ bộ tạo phẩm dữ liệu mà Explorer yêu cầu, bao gồm các tệp chi tiết cho từng hoạt động API, mẫu mã đa ngôn ngữ, cây điều hướng được phân loại và chỉ mục tìm kiếm toàn văn bản. Các API đã thêm và sửa đổi được đánh dấu bằng nhãn thay đổi, trong khi các API đã xóa được giữ lại trong danh mục “Đã xóa gần đây”, đảm bảo rằng các nhà phát triển có thể nhận biết được toàn bộ quá trình phát triển của giao diện.
Trên toàn bộ quy trình, bốn nguyên tắc thiết kế sau đây được áp dụng xuyên suốt:
Ổ đĩa tăng dần: Khác biệt vênh vang được sử dụng làm tín hiệu kích hoạt duy nhất và chỉ các hoạt động API đã thực sự thay đổi mới được xử lý, tránh lãng phí tài nguyên và xáo trộn tệp không cần thiết do việc xây dựng lại toàn bộ gây ra.
Truyền báo cáo theo chuỗi: Mỗi giai đoạn xuất ra một báo cáo JSON được tiêu chuẩn hóa. Các giai đoạn xuôi dòng tự động trích xuất các tham số đầu vào từ các báo cáo ngược dòng, cho phép ghép nối lỏng lẻo và gỡ lỗi độc lập.
Chủ nghĩa quyết định thứ nhất: Tất cả sáu giai đoạn đều được xây dựng trên logic Python xác định để đảm bảo đầu ra nhất quán cho cùng một đầu vào. AI chỉ tham gia vào việc điều phối và giải thích.
Nguồn sự thật duy nhất: swagger.json và DITA Ditamaps được sử dụng làm nguồn đáng tin cậy duy nhất mà từ đó các tạo phẩm PDF và API Explorer được tạo ra một cách thống nhất, loại bỏ sự không nhất quán giữa các kênh.
1.Trí tuệ lai: Phân chia lao động chiến lược giữa AI và các quy tắc xác định
Trong tự động hóa tài liệu API, dịch thuật là một khả năng quan trọng trong toàn bộ chuỗi, nhưng đặc điểm của các mục tiêu dịch thuật khác nhau sẽ khác nhau đáng kể. Tên API yêu cầu tính nhất quán nghiêm ngặt: cùng một OperationId phải ánh xạ ổn định tới cùng một tiêu đề tiếng Trung, nếu không các nhà phát triển sẽ nhầm lẫn. Ngược lại, các mô tả API là ngôn ngữ tự nhiên và chú trọng hơn đến tính trôi chảy và chính xác về mặt ngữ nghĩa. Nếu cả hai đều được xử lý thống nhất bởi một mô hình lớn, tên tuổi có xu hướng trôi đi; nếu cả hai đều dựa hoàn toàn vào các quy tắc thì chất lượng mô tả khó được đảm bảo.
Vì lý do này, hệ thống áp dụng chiến lược kết hợp các quy tắc xác định cộng với AI và khớp chính xác các phương pháp kỹ thuật với đặc điểm của từng mục tiêu dịch. Để dịch tên API, nó sử dụng công cụ phân tích ngữ nghĩa có cấu trúc tự phát triển. Đầu tiên, nó duy trì hơn 570 ánh xạ ghi đè chính xác để xử lý việc đặt tên không đều. Nếu không có ánh xạ nào được thực hiện, nó sẽ phân tách OperationId trong PascalCase và thực hiện nhận dạng động từ, phát hiện mẫu By{Scope} và khớp cụm từ cấp độ 4→3→2→1 theo trình tự để tạo ra các tiêu đề tiếng Trung có cấu trúc. Toàn bộ quá trình mang tính quyết định, đảm bảo đầu ra nhất quán cho cùng một đầu vào. Trong khi đó, bản dịch mô tả API được xử lý theo lô bằng một mô hình ngôn ngữ lớn, với chất lượng được kiểm soát thông qua các ràng buộc về thuật ngữ và giới hạn độ dài không quá 60 ký tự.
Ngoài ra, nguyên tắc xác định trước tiên cũng được áp dụng cho bản dịch từ tiếng Trung sang tiếng Anh ở Giai đoạn 3. Do bộ từ vựng của tài liệu API do máy tạo ra bị đóng nên hệ thống sẽ hoàn thành tất cả bản dịch thông qua quy trình thay thế chuỗi chín bước, sau đó kiểm tra mọi ký tự tiếng Trung còn lại bằng cách quét các phạm vi Unicode ở cuối. Nếu trình tạo giới thiệu từ vựng mới trong tương lai và bảng dịch không được cập nhật tương ứng, cơ chế kiểm tra sẽ tự động đưa ra cảnh báo thay vì âm thầm tạo ra một phần nội dung chưa được dịch.
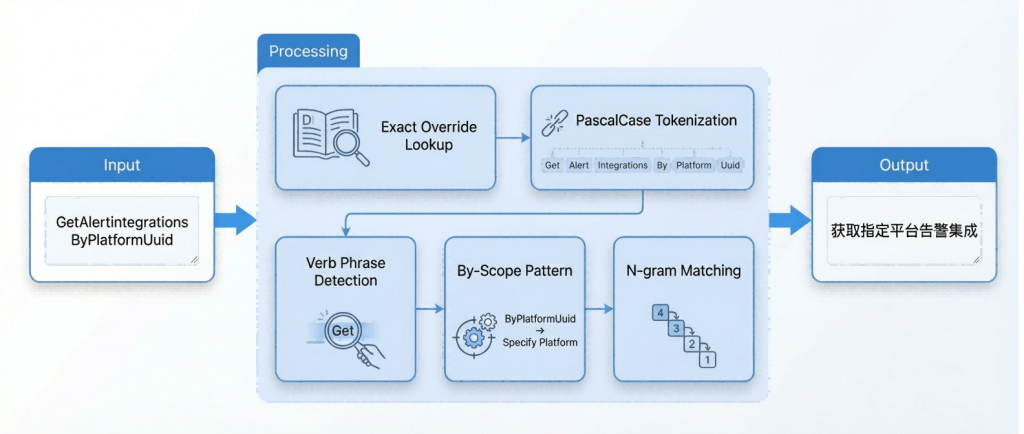
Hình 4. Quy trình phân tích cú pháp ngữ nghĩa có cấu trúc để dịch tên API
2.Phân tích ngữ nghĩa sâu của thông số kỹ thuật Swagger phức tạp
Về lý thuyết, đặc tả Swagger/OpenAPI là một tiêu chuẩn rõ ràng để mô tả các giao diện. Tuy nhiên, trong thực tế kỹ thuật thực tế, các tệp swagger.json được tạo tự động bởi các khung phụ trợ thường chứa một số lượng lớn các trường hợp biên. Nhiều API ZCF liên quan đến các mô hình dữ liệu lồng nhau phức tạp và hệ thống phải đối mặt với ba thách thức điển hình trong quá trình phân tích cú pháp.
Tài liệu tham khảo tròn: Một số mô hình dữ liệu hình thành sự phụ thuộc theo chu kỳ thông qua $ref. Hệ thống giới thiệu một bộ tham chiếu đã truy cập trong quá trình phân tích cú pháp đệ quy và dừng khi gặp lại một tham chiếu, ngăn chặn việc mở rộng vô hạn.
tất cảCác mẫu bố cục: Khi nhiều lược đồ kế thừa thông qua allOf, việc hợp nhất đơn giản sẽ mất đi các ràng buộc. Hệ thống thực hiện hợp nhất sâu bằng cách lấy liên kết loại bỏ trùng lặp của các trường bắt buộc và hợp nhất các thuộc tính theo cách đệ quy để đảm bảo các ràng buộc được giữ nguyên hoàn toàn.
Văn bản mô tả bất thường: Một số mô tả là tên trường được nối, chẳng hạn như cảnh báo tích hợpplatformuuid. Hệ thống phát hiện những trường hợp này bằng biểu thức chính quy và bỏ qua việc dịch nghĩa đen. Sau đó, nó sẽ phân chia trường theo quy tắc trường hợp lạc đà và kết hợp nó với bảng thuật ngữ thuật ngữ để tạo ra các mô tả có thể đọc được.
3. Cổng chất lượng được mã hóa và vòng xác thực nhiều lớp
Trong quy trình hoàn toàn tự động, câu hỏi tin cậy quan trọng nhất là làm thế nào để đảm bảo rằng chất lượng của tài liệu được tạo ra không thấp hơn tiêu chuẩn viết thủ công. Các giải pháp truyền thống dựa vào việc xem xét thủ công, việc này tốn thời gian và không nhất quán giữa người đánh giá này với người đánh giá khác. Hệ thống này xây dựng một hệ thống đảm bảo chất lượng tự động tiến bộ ba lớp, biến các tiêu chuẩn chất lượng từ kinh nghiệm thành mã.
Lớp đầu tiên là xác thực mô phỏng tĩnh trong Giai đoạn 2. Lớp này thực hiện xác thực chéo bảy chiều giữa Swagger và DITA, bao gồm tên, đường dẫn, tham số, nội dung yêu cầu, mẫu Curl, phản hồi và mẫu SDK, đồng thời có thể phát hiện sai lệch mà không cần khởi động bất kỳ dịch vụ nào. Nội dung yêu cầu được xác thực bằng chiến lược nguồn kép dựa trên cả bảng tham số và mẫu Curl để bao quát các đường dẫn tạo khác nhau.
Lớp thứ hai là cổng chất lượng được mã hóa trong Giai đoạn 4. 22 quy tắc bao gồm cấu trúc, nội dung, định dạng và chất lượng bản dịch và được triển khai dưới dạng các chức năng thuần túy. Các tệp tiếng Trung và tiếng Anh được xem xét trong cùng một vòng và bất kỳ lỗi nào sẽ ngay lập tức chặn quy trình, ngăn chặn sự cố khi nhập bản dựng PDF.
Lớp thứ ba là xác thực tính nhất quán của giao diện tài liệu thời gian chạy. Sau khi xuất bản, tài liệu được so sánh với các dịch vụ API đang chạy thực tế trên nhiều khía cạnh chất lượng, chẳng hạn như tham số yêu cầu, cấu trúc phản hồi và dữ liệu mẫu, sử dụng hành vi thời gian chạy làm cơ sở cuối cùng để xác thực. Ba lớp tiến triển từng bước: so sánh tĩnh đảm bảo rằng tài liệu phù hợp với đặc điểm kỹ thuật, các cổng được mã hóa đảm bảo rằng tài liệu đáp ứng các tiêu chuẩn kỹ thuật và xác thực thời gian chạy đảm bảo rằng tài liệu phù hợp với hành vi thực tế. Chúng cùng nhau tạo thành một vòng chất lượng khép kín từ thế hệ này sang thế hệ khác.
Ngoài ra, đối với một số ít trường hợp trong đó lược đồ Swagger được xác định không chính xác, chẳng hạn như khi cấu trúc mô hình phản hồi không khớp với hành vi API thực tế, hệ thống sẽ cung cấp các bản vá ghi đè lược đồ chính xác. Các bản vá này khắc phục sự cố trong quá trình phân tích cú pháp, chuyển bản sửa lỗi cho những khác biệt về logic nghiệp vụ sang lớp nguồn dữ liệu thay vì liên tục vá các giai đoạn tạo ở phía dưới.
1.Tự động hóa từ đầu đến cuối với hiệu quả đạt được đáng kể
Tự động hóa từ đầu đến cuối dựa trên tác nhân AI nén quy trình cập nhật tài liệu API từ so sánh từng cái một, viết thủ công, dịch riêng và các bản dựng riêng biệt thành một quy trình công việc duy nhất trong đó thay đổi Swagger phụ trợ sẽ kích hoạt theo dõi tự động trên toàn bộ chuỗi tài liệu. Trong quy trình làm việc thực tế, hệ thống giám sát các thay đổi đối với tệp Swagger thông qua kiểm soát phiên bản Git và tự động kích hoạt tất cả các giai đoạn tiếp theo ngay khi phát hiện thay đổi, không cần can thiệp thủ công trong suốt quá trình. Đồng thời, cơ chế truyền động gia tăng đảm bảo hệ thống chỉ xử lý các hoạt động API đã thay đổi thay vì xây dựng lại mọi thứ, nâng cao hiệu quả hơn nữa. Cho dù đối với những lần lặp lại nhỏ thường lệ hay thay đổi API quy mô lớn, việc xuất bản tài liệu đa kênh đều có thể được hoàn thành nhanh chóng và ổn định.
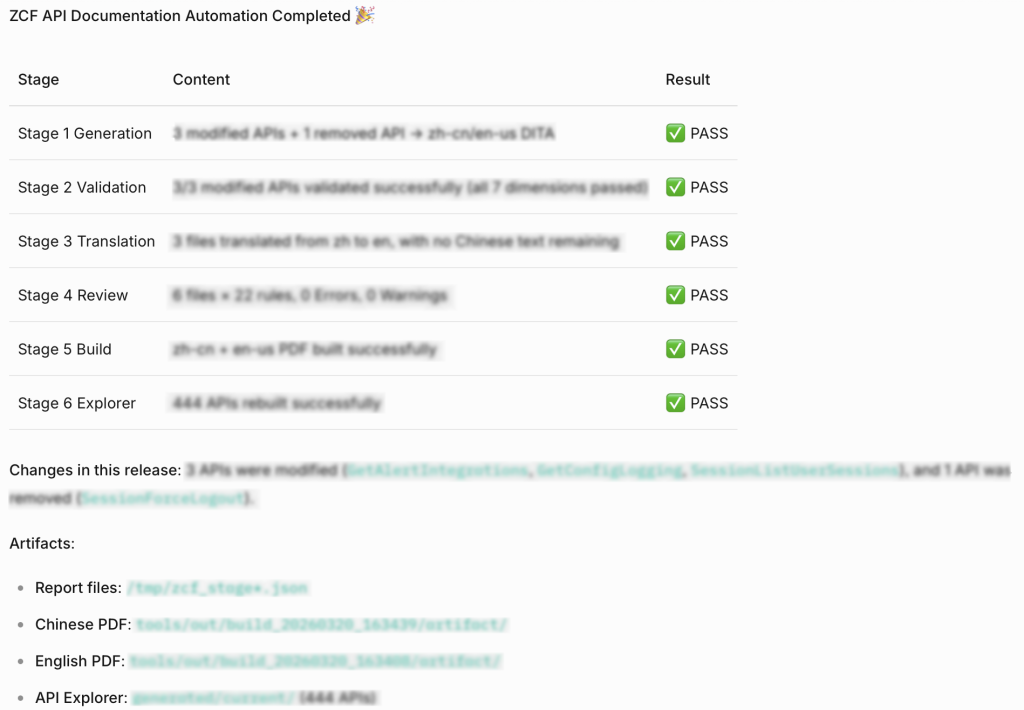
Hình 5. Báo cáo giai đoạn và quy trình thực hiện đường ống
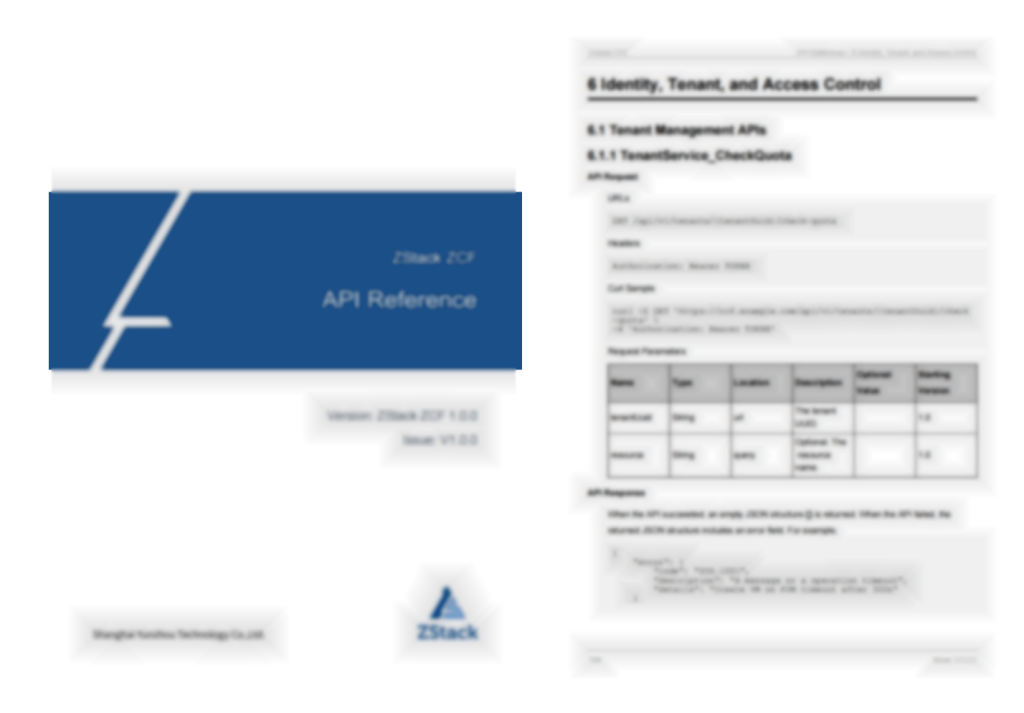
Hình 6. Trang hướng dẫn phát triển PDF được tạo tự động
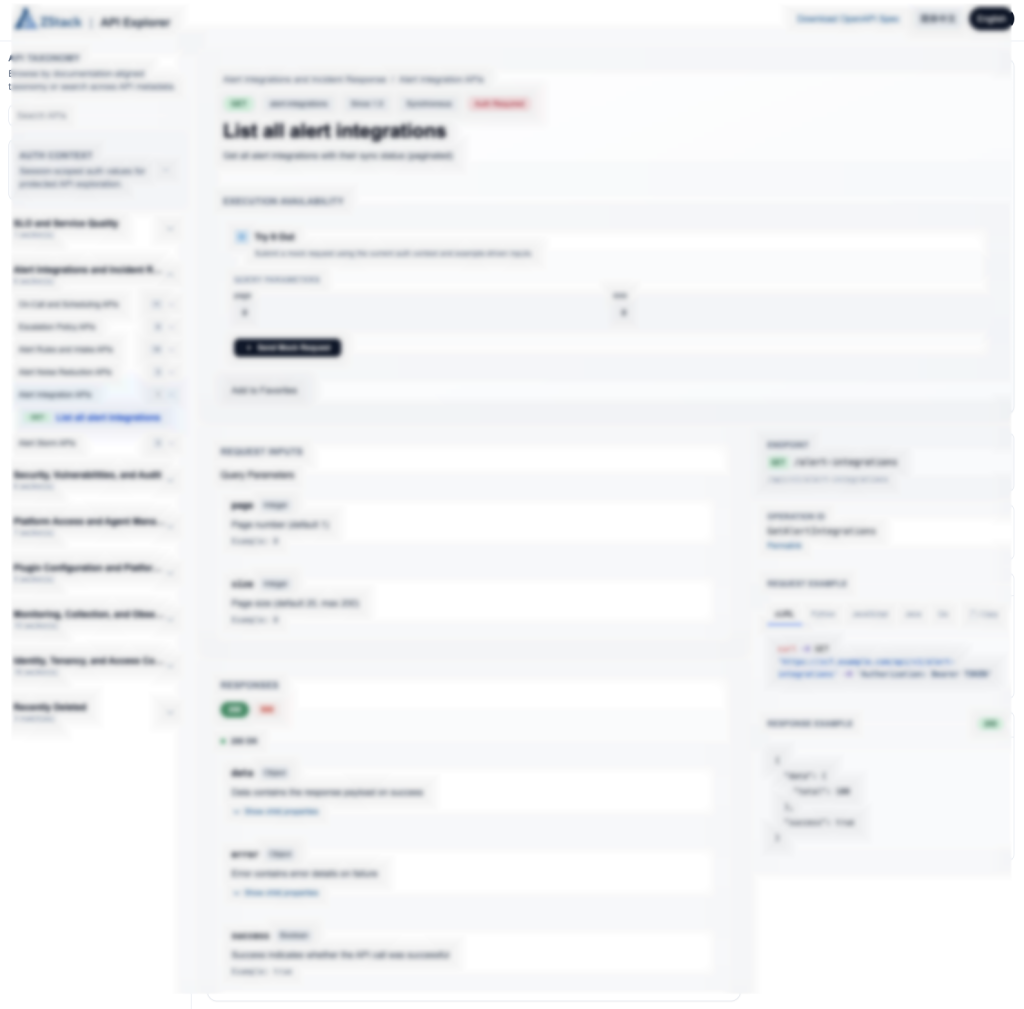
Hình 7. API Explorer (Hiện có trong Trung tâm Tài liệu ZSite)
Trung tâm Tài liệu ZSite hiện đã hoạt động và API Explorer có sẵn dưới dạng phần cốt lõi dành cho nhà phát triển trong đó. Từ một cổng tài liệu, người dùng có thể tìm kiếm tài liệu sản phẩm, duyệt danh mục API, tìm hoạt động theo từ khóa, xem mẫu mã đa ngôn ngữ và theo dõi các thay đổi của phiên bản, chuyển từ đọc tài liệu sản phẩm sang khám phá giao diện, kiểm tra ví dụ và hiểu sự phát triển của API một cách tự nhiên. Để xem ZStack API Explorer, hãy truy cập https://docs.zstack-cloud.com/docs/api-explorer/en; để biết thêm tài liệu về sản phẩm, hãy truy cập https://docs.zstack-cloud.com/en.
2. Chất lượng có thể kiểm soát và tiêu chuẩn thống nhất
Nền tảng biến các tiêu chuẩn chất lượng tài liệu từ những đánh giá chủ quan dựa trên kinh nghiệm cá nhân thành việc thực thi tự động 22 quy tắc được mã hóa, đảm bảo rằng mọi tài liệu đầu ra đều được xem xét với mức độ nghiêm ngặt như nhau. Các tệp tiếng Trung và tiếng Anh được xem xét đồng thời trong cùng một lượt và mọi phát hiện ở cấp độ lỗi sẽ tự động chặn quy trình, ngăn chặn một cách máy móc nội dung không tuân thủ đi vào giai đoạn xuất bản. Đồng thời, logic dịch thuật và tạo xác định đảm bảo khả năng tái tạo: với cùng một đầu vào Swagger, hệ thống luôn tạo ra nội dung tài liệu giống hệt nhau, bất kể khi nào nó chạy hay ai kích hoạt nó, loại bỏ hoàn toàn sự khác biệt về phong cách và sự biến động về chất lượng trong cộng tác nhiều người.
Sự phát triển kỹ thuật của tài liệu API về cơ bản là sự theo đuổi liên tục tam giác chất lượng về độ chính xác, kịp thời và nhất quán. Bằng cách giới thiệu các tác nhân AI làm công cụ điều phối, nhóm tài liệu ZStack đã kết nối toàn bộ chuỗi từ các thay đổi đặc tả Swagger đến xuất bản tài liệu đa kênh vào một quy trình tự động và tìm thấy sự cân bằng bền vững giữa hiệu quả và chất lượng. Thực tiễn này xác nhận một lộ trình kỹ thuật trong đó AI và kỹ thuật xác định bổ sung cho nhau: AI đóng góp sự hiểu biết về ngữ nghĩa và ra quyết định thông minh, trong khi các quy tắc xác định bảo vệ điểm mấu chốt của tính nhất quán và khả năng tái tạo.
Trong tương lai, chúng tôi sẽ tiếp tục khám phá nhiều khả năng hơn cho AI trong kỹ thuật tài liệu và mong muốn được hợp tác với các đồng nghiệp trong ngành để cùng nhau phát triển hướng đi này.