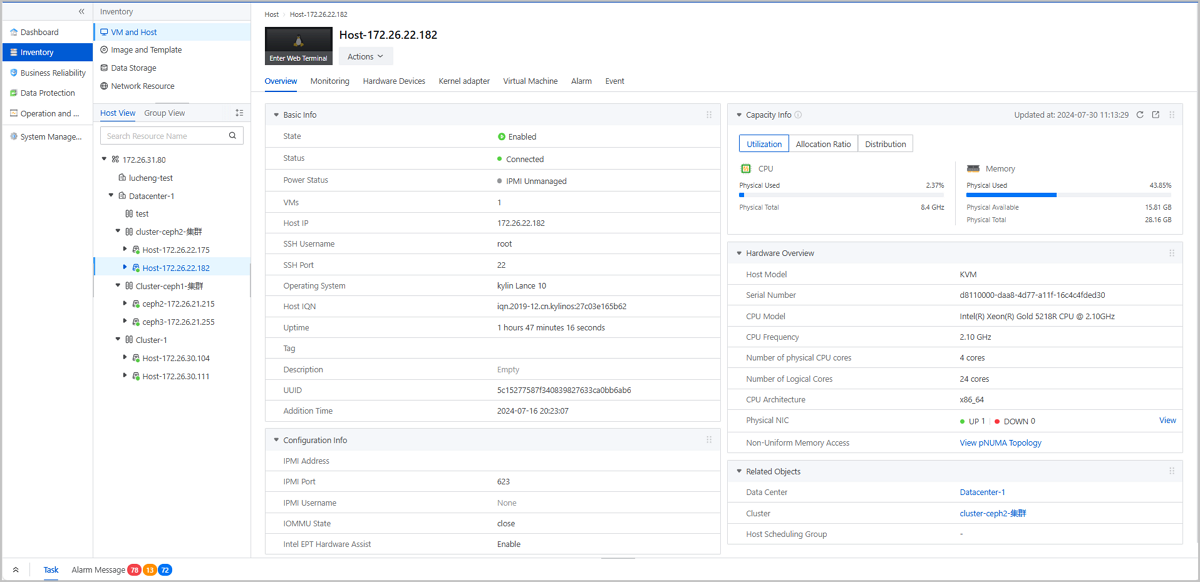
Nền tảng đám mây ZStack
Triển khai một máy chủ với đầy đủ tính năng, miễn phí trong một năm

Tài liệu và công cụ sản phẩm toàn diện

Đề cao giá trị của Khách hàng là trên hết và sứ mệnh Phục vụ Khách hàng, ZStack tận tâm cung cấp các dịch vụ an toàn và ổn định cho khách hàng.

Để giáo dục các đối tác của ZStack và những cá nhân quan tâm về điện toán đám mây và trau dồi tài năng về điện toán đám mây.

ZStack cung cấp cơ sở hạ tầng đám mây sáng tạo cho mười ngành công nghiệp chính

Thông qua ba phần chính, hàng chục ngàn từ và hơn 10 khách hàng đại diện toàn cầu
Trong thời đại trí tuệ nhân tạo phát triển nhanh chóng, mỗi bước nhảy vọt về công nghệ giống như thả một hòn đá lớn xuống hồ công nghiệp, khuấy động vô số gợn sóng. Vào ngày 20 tháng 1 năm 2025, DeepSeek-R1 đã có màn ra mắt ấn tượng, ngay lập tức khơi dậy sự phấn khích trong cộng đồng AI và trở thành trung tâm của sự chú ý. Hiệu suất vượt trội của DeepSeek-R1 đã làm dấy lên cuộc thảo luận rộng rãi và chúng tôi chắc chắn rằng bạn tò mò về nó. Vậy logic nào thúc đẩy việc tạo ra những mô hình này? Họ được đào tạo như thế nào? Có sự khác biệt nào giữa các mô hình và kịch bản nào phù hợp với từng mô hình? Hôm nay, chúng ta sẽ sử dụng ngôn ngữ đơn giản, rõ ràng nhất để nhanh chóng bộc lộ những điểm mạnh vượt trội của DeepSeek-R1.
Hành trình của các mô hình DeepSeek phản ánh sự kết hợp giữa đổi mới và tiến hóa, đỉnh cao là dòng R1 mạnh mẽ. Hãy chia nhỏ nó ra từng bước một.
Gần đây, DeepSeek đã thu hút được sự chú ý toàn cầu với R1. Chúng ta hãy theo dõi ngắn gọn dòng thời gian phát triển mô hình của DeepSeek:
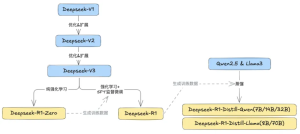
DeepSeek-R1 không phải là sản phẩm của một hoặc hai phương pháp đào tạo kết hợp với nhau. Nó phát triển từ V1 qua nhiều phiên bản. Mỗi cái được xây dựng dựa trên cái cuối cùng, hợp nhất các phương pháp đào tạo khác nhau. Hơn nữa, DeepSeek-R1 còn áp dụng các nguyên tắc nguồn mở. Nó có sẵn miễn phí cho các nhà phát triển toàn cầu. Điều này làm giảm rào cản cho các nhà nghiên cứu và doanh nghiệp sử dụng các mô hình tiên tiến. Nó thúc đẩy tiến bộ AI toàn cầu. Người đoạt giải Turing và Nhà khoa học AI trưởng của Facebook Yann LeCun đã ca ngợi nó là “nguồn mở chiến thắng nguồn đóng”.
Kích thước tham số lớn của DeepSeek-R1 đòi hỏi nguồn lực triển khai cao. Để đưa lý luận chuỗi dài vào các mô hình nhỏ hơn, nhóm DeepSeek đã áp dụng phương pháp chưng cất. Hãy coi việc chắt lọc mô hình như một sự chuyển giao kiến thức. Hãy sử dụng DeepSeek-R1-Distill-Qwen2.5-7B làm ví dụ để giải thích quy trình một cách đơn giản:
Chưng cất mô hình mang lại một số lợi ích. Từ quan điểm chi phí và hiệu quả, các mô hình chưng cất nhỏ gần như có thể sánh ngang với hiệu suất của các mô hình lớn. Điều này cắt giảm chi phí triển khai doanh nghiệp và tăng tốc độ lý luận. Nó cũng làm giảm sự phụ thuộc vào tài nguyên máy tính khổng lồ. Tuy nhiên, vì về cơ bản nó vẫn là Qwen hoặc Llama nên cần có sự hiểu biết và thử nghiệm cẩn thận để đáp ứng nhu cầu kinh doanh trong thế giới thực.
Một kỹ thuật quan trọng khác để vận hành mô hình hiệu quả là “lượng tử hóa” mà chúng ta sẽ khám phá tiếp theo.
Như đã đề cập, DeepSeek-R1 thực sự là phiên bản có thông số 671B (trên mạng thường gọi là phiên bản “toàn năng”). Tuy nhiên, nhiều hướng dẫn hướng dẫn người dùng tải xuống Qwen2.5 7B đã được chắt lọc và tinh chỉnh thông qua “ollama run deepseek-r1”. “Trí thông minh” của phiên bản này khác rất nhiều so với mô hình trên trang web chính thức của DeepSeek. Hãy nhìn kỹ - nó chỉ có 4,7GB. Điều này cho thấy lượng tử hóa nặng. Việc nén như vậy càng làm suy yếu “trí thông minh” của nó.
Lượng tử hóa chuyển đổi trọng số và kích hoạt của mô hình từ độ chính xác cao (ví dụ: FP32, BF16) sang độ chính xác thấp (ví dụ: INT8 hoặc INT4). Bằng cách giảm độ rộng bit cho mỗi tham số, nó sẽ giảm nhu cầu lưu trữ và tính toán. Các mô hình lượng tử hóa cắt giảm nhu cầu sử dụng và xử lý bộ nhớ. Điều này cho phép triển khai mô hình lớn trên GPU tiêu chuẩn hoặc thậm chí cả CPU. Tuy nhiên, lượng tử hóa quá mức có thể gây tổn hại đến độ chính xác, đặc biệt đối với các nhiệm vụ cần tính toán và lý luận chính xác.
Đối với các mô hình suy luận, kết quả đầu ra thường bao gồm các chuỗi mã thông báo dài và yêu cầu độ chính xác cao. Vì vậy, nên lượng tử hóa FP16 hoặc INT8. Những phương pháp này làm giảm nhu cầu tài nguyên trong khi vẫn duy trì được hiệu suất của mô hình.
Lưu ý rằng các công cụ lượng tử hóa mới (ví dụ: Llama.cpp) cung cấp khả năng xử lý tinh chỉnh. Ví dụ: họ áp dụng độ chính xác khác nhau (4 bit, 6 bit, 32 bit) cho các lớp khác nhau. Điều này tạo ra các tùy chọn như Q4_K_M hoặc Q6. Tuy nhiên, vấn đề vẫn là cân bằng giữa độ chính xác, tốc độ và việc sử dụng tài nguyên.
Các mô hình ban đầu của DeepSeek rất lớn. Ngay cả ở Int4, nhu cầu bộ nhớ vẫn ở mức cao. Kiến trúc và mô hình lý luận của MoE đặt ra những thách thức về lượng tử hóa. Các phương pháp nâng cao như lượng tử hóa hỗn hợp 1,58 hoặc 2,51 hoặc lượng tử hóa động có thể hữu ích. Chúng tôi sẽ trình bày chi tiết về tác dụng và lượng tử hóa bối cảnh của chúng trong các bài viết sau.
Tuy nhiên, ngay cả sau khi lượng tử hóa, trí nhớ vẫn có thể bị thiếu hụt. Hoặc đầu ra có thể bị cắt bớt trong thời gian chạy. Điều này gắn liền với một yếu tố mô hình quan trọng khác: “cửa sổ ngữ cảnh”.
Mô hình dừng lại trước khi kết thúc quá trình suy luận. Đầu ra của nó đạt đến giới hạn “độ dài tối đa”. cho tìm kiếm sâuAPI chính thức của, chuỗi suy luận tối đa là 32K, với đầu ra tối đa là 8K. Mô hình ban đầu hỗ trợ ngữ cảnh lên tới 164K—tổng cộng khoảng 100.000 đến 160.000 từ. Nhưng bối cảnh dài như vậy sẽ tiêu tốn nguồn tài nguyên khổng lồ. Vì vậy, một số API giới hạn đầu ra và ngữ cảnh tối đa. Các mô hình không suy luận cũ hơn có thể quản lý bằng ngữ cảnh 4K cho mỗi cuộc trò chuyện. Tuy nhiên, các mô hình lý luận sử dụng ngữ cảnh để “suy nghĩ”. Do đó, 4K thường không đủ cho một phiên, khiến người dùng khó chịu.
Cửa sổ ngữ cảnh là số lượng mã thông báo tối đa mà một mô hình có thể xử lý trong một lần lý luận. Tỷ lệ mã thông báo trên từ thay đổi đôi chút tùy theo mô hình. Ngữ cảnh dài hơn cho phép người mẫu nhớ lại và nắm bắt được nhiều văn bản hơn. Điều này quan trọng đối với việc tạo văn bản dài và các tác vụ phức tạp, như tạo mã quy mô lớn hoặc phân tích nội dung chuyên nghiệp.
Việc sử dụng bộ nhớ mô hình bao gồm:
Đây là những ước tính sử dụng độ chính xác BF16. GPU hỗ trợ FP8 có thể khác nhau. Việc sử dụng ngữ cảnh được tính toán thông qua llama.cpp; các khung như vllm có thể sử dụng nhiều hơn. Các yêu cầu đồng thời cần thêm KV Cache mỗi phiên.
Hiệu suất thực tế thay đổi tùy theo phần cứng và mức độ tối ưu hóa. Trong thử nghiệm này, với 16 người dùng đồng thời, thông lượng đạt mức cao nhất. Mỗi người dùng nhận được ~42 mã thông báo/giây, với độ trễ của mã thông báo đầu tiên dưới 0,2 giây.
MMLU (Hiểu ngôn ngữ đa nhiệm lớn) đánh giá khả năng hiểu đa nhiệm. Chúng tôi đã so sánh điểm MMLU của mô hình 7B trước và sau quá trình chưng cất.
Sau quá trình chưng cất, điểm số giảm xuống và thời gian lý luận kéo dài đáng kể.
Chúng tôi đã thử nghiệm các vấn đề logic cổ điển:
Chúng tôi đã thử nghiệm RAG với báo cáo DeepSeek V3 và R1 (22 trang, 8802 từ; 53 trang, 22330 từ) trong cơ sở kiến thức Dify của AIOS. Những điều này không có trong dữ liệu đào tạo trước, buộc các câu trả lời phải dựa trên mức độ hiểu. Không có chỉnh sửa kịp thời; Bối cảnh 8K; cài đặt mặc định. Các câu trả lời được tính trung bình trên nhiều truy vấn.
Nhờ có ZStack Môi trường được tối ưu hóa của AIOS, vector hóa tài liệu và phản hồi nhanh chóng. Kết quả cho thấy:
Trong các bài viết tiếp theo, chúng ta sẽ khám phá:
Bằng cách so sánh kích thước và độ chính xác, chúng tôi mong muốn cung cấp các kế hoạch triển khai chi tiết cho doanh nghiệp. Điều này sẽ giúp các ngành áp dụng các mô hình ngôn ngữ lớn một cách nhanh chóng, mở ra giá trị kinh doanh.
Bắt đầu với sự phát triển của DeepSeek, bài viết này khám phá vai trò của quá trình chắt lọc và lượng tử hóa trong quá trình triển khai. Qua dữ liệu và thử nghiệm, chúng tôi thấy mô hình 7B chắt lọc có lý luận cân bằng và chi phí hợp lý. Chúng tôi hy vọng điều này cung cấp những hiểu biết hữu ích cho việc sử dụng mô hình ngôn ngữ lớn của doanh nghiệp. Bạn tò mò về việc triển khai và đánh giá mô hình 32B hoặc 671B? Hãy theo dõi các bài viết tiếp theo của chúng tôi!
 2024-12-12
2024-12-12