Nền tảng đám mây ZStack
Triển khai một máy chủ với đầy đủ tính năng, miễn phí trong một năm

Tài liệu và công cụ sản phẩm toàn diện

Đề cao giá trị của Khách hàng là trên hết và sứ mệnh Phục vụ Khách hàng, ZStack tận tâm cung cấp các dịch vụ an toàn và ổn định cho khách hàng.

Để giáo dục các đối tác của ZStack và những cá nhân quan tâm về điện toán đám mây và trau dồi tài năng về điện toán đám mây.

ZStack cung cấp cơ sở hạ tầng đám mây sáng tạo cho mười ngành công nghiệp chính

Thông qua ba phần chính, hàng chục ngàn từ và hơn 10 khách hàng đại diện toàn cầu
Trong loạt bài Hiểu biết sâu sắc về DeepSeek và thực tiễn doanh nghiệp (Phần 1): Chắt lọc, triển khai và đánh giá và Hiểu biết sâu sắc về DeepSeek và thực tiễn doanh nghiệp (Phần 2): Nguyên tắc, làm mát phần cứng và kiểm tra hiệu suất của suy luận đa GPU 32B, chúng tôi đã giới thiệu mối quan hệ giữa các mô hình DeepSeek R1 khác nhau, các số liệu cốt lõi, đồng thời hoàn thành việc triển khai và đánh giá một số mô hình chắt lọc trên ZStack AIOS. Theo thử nghiệm của chúng tôi, các phiên bản chắt lọc thường hoạt động tốt hơn các mô hình ban đầu trong các lĩnh vực như toán học và mã hóa. Tuy nhiên, đối với các tác vụ phức tạp hơn (ví dụ: viết hàng trăm dòng mã), hiệu suất của chúng có thể bị giảm sút. Tại thời điểm này, chúng ta cần cân nhắc việc sử dụng mẫu DeepSeek-R1 671B, thường được gọi trên mạng là “phiên bản toàn năng”.
Tuy nhiên, với tham số 671B, mô hình rất đồ sộ. Nếu phần cứng không hỗ trợ FP8 thì chỉ riêng trọng lượng của mô hình đã yêu cầu 1,3TB, khiến chi phí tăng cao. Vì vậy, bài viết này tập trung vào việc triển khai mô hình DeepSeek-R1 671B gần nghìn tỷ tham số với chi phí thấp nhất, đánh giá hiệu suất trong thế giới thực của các phiên bản lượng tử hóa, đánh giá mức độ tổn thất so với các phiên bản không lượng tử hóa và phân tích hiệu quả chi phí cũng như các kịch bản phù hợp cho các cấu hình phần cứng khác nhau.
Hiện nay có rất nhiều phương pháp lượng tử hóa tìm kiếm sâu R1 671B. Chúng tôi sẽ không đi sâu vào ý nghĩa cụ thể của các phương pháp như IQ_1_S hoặc AWQ ở đây. Thay vào đó, chúng tôi so sánh trực tiếp một số sơ đồ điển hình và Yêu cầu VRAM dưới đây:
(Lưu ý: Yêu cầu VRAM bao gồm bộ đệm KV tối thiểu và chi phí hệ thống và thể hiện nhu cầu thấp nhất. Yêu cầu thực tế phụ thuộc vào kích thước cửa sổ ngữ cảnh, độ chính xác của bộ đệm KV, v.v. để ước tính chính xác. Các định dạng GGUF và safetensor khác nhau trong cách sử dụng VRAM do công cụ suy luận và phương pháp song song nên không thể so sánh trực tiếp.)
Từ bảng trên, có thể thấy rõ rằng một máy chủ 3090 8-GPU đáp ứng hoàn hảo các yêu cầu tối thiểu cho 671B-1.58b! Ngoài ra, tất cả trọng lượng có thể được tải lên GPU, đảm bảo tốc độ suy luận khá. Tuy nhiên, lưu ý rằng vì định dạng là GGUF nên cần có khung suy luận llama.cpp. trong ZStack AIOS, hỗ trợ nhiều khung suy luận, cho phép người dùng lựa chọn dựa trên nhu cầu của mình.
1. Chuẩn bị môi trường: Cài đặt ZStack AIOS và đảm bảo hệ thống đáp ứng yêu cầu vận hành.
2. Triển khai bằng một cú nhấp chuột:
aSử dụng ZStack AIOS để chọn mô hình và liên kết nó với mẫu suy luận thích hợp (llama.cpp) và hình ảnh.
b. Chỉ định GPU và tính toán các thông số kỹ thuật để chạy mô hình, sau đó triển khai.
3. Chạy thử: Thử trải nghiệm hội thoại trong cửa sổ tương tác hoặc tích hợp qua API vào các ứng dụng khác.
Chúng tôi đã chạy thành công 671B-1.58b! Thật không may, chúng tôi bị giới hạn ở bối cảnh 4K do cách tiếp cận tải GPU theo lớp của llama.cpp, trong đó mỗi lớp yêu cầu kích thước bối cảnh đầy đủ để hoạt động. Hơn nữa, do cơ chế suy luận của llama.cpp, việc tăng tính đồng thời không làm tăng tổng thông lượng và thậm chí còn làm giảm kích thước bối cảnh mỗi phiên. Vì vậy, chúng tôi đã không theo đuổi tính đồng thời cao hơn.
Tuy nhiên, bối cảnh 4K là quá nhỏ đối với DeepSeek-R1. Các câu trả lời dễ bị cắt ngắn, khiến không thể hoàn thành các đánh giá tiêu chuẩn như MMLU hoặc C-EVAL. Để tăng kích thước ngữ cảnh, chúng tôi đã thử nghiệm triển khai DeepSeek-R1-671B-1.58b trên nhiều máy.
Do ngữ cảnh trên một chiếc 3090 quá hạn chế nên chúng tôi đã mở rộng ngữ cảnh của mô hình 671B-1.58b thông qua một cụm. Bằng cách phân bổ trọng số trên 16 thẻ, về mặt lý thuyết, chúng tôi đã thu được gần 14GB dung lượng cho KV Cache, tương đương với khoảng 14K không gian ngữ cảnh. (Lưu ý: Suy luận song song nhiều máy với llama.cpp không được khuyến nghị cho sản xuất; tính năng này chỉ dành cho thử nghiệm.)
Các kịch bản ngữ cảnh dài cho thấy thông lượng mô hình tăng nhẹ.
Do kiến trúc của llama.cpp và giới hạn băng thông của 3090, tính đồng thời cao hơn không cải thiện hiệu quả việc sử dụng GPU.
Bằng cách sử dụng tính năng đánh giá dịch vụ của ZStack AIOS, chúng tôi đã thử nghiệm DeepSeek-R1-671B-1.58b trên MMLU, C-Eval, HumanEval, v.v., so sánh hiệu suất lượng tử hóa của nó giữa các kích thước và với các phiên bản chắt lọc.
Do thời gian chạy quá dài nên một số đánh giá đã được lấy mẫu. Kết quả được tóm tắt dưới đây:
*Dữ liệu được đánh dấu là đã được kiểm tra trong ZStack môi trường thử nghiệm, không phải dữ liệu giấy chính thức.
**Chỉ với bối cảnh 14K, thử nghiệm AIME24 không thể hoàn thành bình thường.
Từ dữ liệu, lượng tử hóa 1,58 phần nào ảnh hưởng đến hiệu suất, nhưng hiệu quả ít nghiêm trọng hơn dự kiến. Nó vẫn có những lợi thế đáng kể so với GPT-4o và Claude-3.5 về khả năng hiểu tiếng Anh, khả năng hiểu tiếng Trung và khả năng mã hóa.
Các mẹo trực tuyến để “xác định mô hình toàn năng” đã được thử nghiệm, cho thấy một số sức mạnh khác biệt:
Bị giới hạn bởi thiết kế của llama.cpp và cấu trúc dữ liệu lượng tử hóa 1,58, việc tăng hiệu suất hơn nữa là một thách thức. Đối với các doanh nghiệp, trong khi một hoặc hai 3090 có hiệu quả về mặt chi phí thì cửa sổ ngữ cảnh và khả năng tương tranh bị hạn chế rất nhiều.
Vì vậy, chúng tôi đã khám phá một phương pháp lượng tử hóa khác—AWQ. Về mặt lý thuyết, AWQ chỉ yêu cầu 8 GPU với 64GB+ VRAM. Do hạn chế về tài nguyên, chúng tôi đã thử nghiệm hiệu suất AWQ với GPU H20 96GB.
Thiết lập môi trường
Kết quả thực hiện
Hình bên dưới cho thấy hiệu suất của các đoạn hội thoại DeepSeek-R1-AWQ trên ZStack AIOS:
Phân tích hiệu suất
1. Lượng tử hóa AWQ không hỗ trợ tăng tốc MLA hoặc FP8, hạn chế hiệu suất trong các tình huống đa đồng thời.
2. Khi tính đồng thời tăng lên, thông lượng có thể đạt gần 400 Token/s, nhưng thông lượng mỗi phiên giảm mạnh, chỉ phù hợp với việc sử dụng ngoại tuyến.
3. Do các phương pháp kiểm tra nghiêm ngặt nên tỷ lệ trúng KV Cache rất thấp. Với những lời nhắc tương tự để tăng tỷ lệ trúng, thông lượng có thể đạt tới 910 TPS.
So sánh khả năng:
Tương tự như 1.58, chúng tôi đã chạy “thử nghiệm phiên bản toàn năng” trực tuyến:
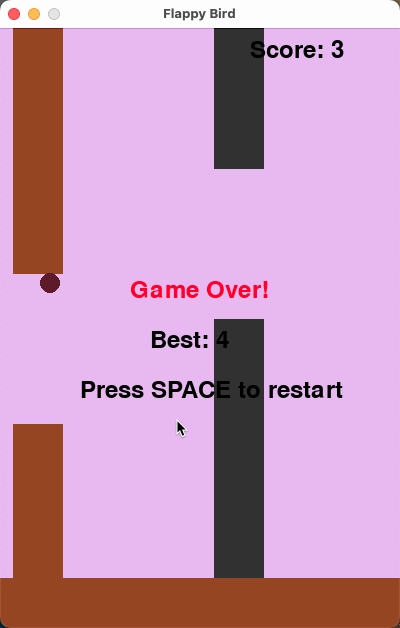
Earlier, we saw that DeepSeek-R1-671B quantization has minimal impact on code generation. However, a HumanEval score of 90 may not be intuitive for readers. Following Unsloth’s testing approach, we tasked the model with creating the Flappy Bird game three times (pass@3). We scored it based on 10 criteria (e.g., random colors, random shapes, successful execution) and averaged the results. Temperature was set to 0.6.
Dưới đây là Lời nhắc được sử dụng:
Tạo trò chơi Flappy Bird trong Python. Bạn phải bao gồm những điều sau:Bạn phải sử dụng pygame. Màu nền phải được chọn ngẫu nhiên và là màu sáng. Bắt đầu với màu xanh nhạt. Nhấn SPACE nhiều lần sẽ tăng tốc con chim. Hình dạng của con chim phải được chọn ngẫu nhiên dưới dạng hình vuông, hình tròn hoặc hình tam giác. Màu sắc nên được chọn ngẫu nhiên là màu tối. Đặt ngẫu nhiên một số vùng đất có màu nâu sẫm hoặc vàng ở phía dưới. Hãy ghi điểm ở phía trên bên phải. Tăng dần nếu bạn vượt qua các đường ống và không chạm vào chúng. Tạo các đường ống có khoảng cách ngẫu nhiên với đủ không gian. Tô màu chúng một cách ngẫu nhiên là xanh đậm hoặc nâu nhạt hoặc xám đậm. Khi bạn thua, hãy hiển thị điểm cao nhất. Tạo văn bản bên trong màn hình. Nhấn q hoặc Esc sẽ thoát khỏi trò chơi. Khởi động lại là nhấn SPACE lại.Trò chơi cuối cùng sẽ nằm trong phần đánh dấu trong Python. Kiểm tra mã của bạn để tìm lỗi và sửa chúng trước khi đến phần đánh dấu cuối cùng.
Các kết quả bên dưới phản ánh kết quả tốt nhất từ ba lượt chạy, với điểm trung bình:
Ngay cả khi tạo mã dài hơn, lượng tử hóa AWQ cho thấy sự suy giảm nhẹ nhưng hiệu suất tổng thể vẫn gần với DeepSeek-R1.
|
_ |
Kết quả thực hiện |
Điểm |
|
DeepSeek-R1-671B-1.58b Lượng tử hóa |
|
78.5% |
|
DeepSeek-R1-671B-AWQ được lượng tử hóa |
|
91.0% |
|
DeepSeek-R1-671B không được định lượng |
|
92.5% |
Ngay cả khi tạo mã dài hơn, lượng tử hóa AWQ cho thấy sự suy giảm nhẹ nhưng hiệu suất tổng thể vẫn gần với DeepSeek-R1.
Giá mẫu GPU rất khác nhau do thông số kỹ thuật phần cứng và nguồn cung thị trường. Ở đây, chúng tôi ước tính dựa trên các nền tảng điện toán trực tuyến phổ biến như AutoDL:
Lưu ý rằng chi phí thuê và mua hàng tháng không phải lúc nào cũng tỷ lệ thuận với nhau. Ví dụ: giá thuê hàng tháng của máy chủ H20 8-GPU cao gấp sáu lần so với máy chủ 3090 8-GPU, nhưng chi phí mua của nó không nhất thiết phải cao hơn sáu lần.
Một 3090 duy nhất phù hợp với thử nghiệm đơn giản, không phù hợp với các nhiệm vụ như toán học hoặc mã hóa (cần ngữ cảnh dài hơn).
Thiết lập Multi-3090 lý tưởng cho các cá nhân hoặc tạo mã quy mô nhỏ, với ngữ cảnh 14K đủ để mã hóa nhưng không cần suy luận toán học phức tạp.
Mặc dù một chiếc 3090 có chi phí thấp nhưng nó lại thiếu lợi thế trong các tình huống sản xuất hàng loạt. Cấu hình cao hơn mang lại hiệu quả chi phí tốt hơn cho các cửa sổ ngữ cảnh lớn hơn và tính song song.
Do nhu cầu tính toán lớn đối với các tham số của mô hình, một người dùng sẽ phải vật lộn để vượt quá tốc độ suy luận 30–50 TPS.
Tuy nhiên, vì DeepSeek còn tương đối mới nên các công cụ suy luận có thể được tối ưu hóa, có khả năng thay đổi kết quả trong tương lai.
Thông qua hoạt động khám phá này, chúng tôi đã thu được những hiểu biết sâu sắc về cách DeepSeek-R1-671B giảm chi phí trải nghiệm thông qua lượng tử hóa 1,58 và chi phí bối cảnh siêu dài thông qua lượng tử hóa AWQ. Chúng tôi đã kiểm tra hiệu năng và khả năng của thời gian chạy, lưu ý rằng khả năng suy luận toán học phức tạp dễ bị mất nhất trong quá trình lượng tử hóa. Ngoài ra, kích thước bối cảnh khi triển khai ảnh hưởng nghiêm trọng đến hiệu suất.
Trong các bài viết tiếp theo, chúng ta sẽ khám phá:
Chiến lược triển khai chính xác hoàn toàn: Cách triển khai đúng các mô hình trong môi trường điện toán hiệu suất cao để tối đa hóa khả năng và tài nguyên phần cứng của mô hình lớn.
Bằng cách so sánh các mô hình có quy mô và độ chính xác khác nhau, chúng tôi mong muốn cung cấp các giải pháp triển khai chi tiết, toàn diện cho các ứng dụng doanh nghiệp, giúp nhiều ngành hơn áp dụng công nghệ mô hình ngôn ngữ lớn một cách nhanh chóng và hiện thực hóa giá trị kinh doanh.
Lưu ý: Một số dữ liệu trong bài viết này mang tính minh họa. Điều kiện thực tế có thể khác nhau, vì vậy nên kiểm tra và xác nhận chi tiết trong quá trình thực hiện.
 2025-02-11
2025-02-11