Nền tảng đám mây ZStack
Triển khai một máy chủ với đầy đủ tính năng, miễn phí trong một năm

Tài liệu và công cụ sản phẩm toàn diện

Đề cao giá trị của Khách hàng là trên hết và sứ mệnh Phục vụ Khách hàng, ZStack tận tâm cung cấp các dịch vụ an toàn và ổn định cho khách hàng.

Để giáo dục các đối tác của ZStack và những cá nhân quan tâm về điện toán đám mây và trau dồi tài năng về điện toán đám mây.

ZStack cung cấp cơ sở hạ tầng đám mây sáng tạo cho mười ngành công nghiệp chính

Thông qua ba phần chính, hàng chục ngàn từ và hơn 10 khách hàng đại diện toàn cầu
I. Lời nói đầu
Sách Sáng thế kể lại câu chuyện về Tháp Babel—câu chuyện về sự đoàn kết ban đầu của nhân loại thông qua ngôn ngữ chung và tham vọng của họ là xây dựng một tòa tháp vươn tới tận trời. Thấy điều này là quá đáng, Chúa đã làm bối rối lời nói của họ. Việc không thể giao tiếp đã khiến việc xây dựng bị đình trệ. Những bức tường vô hình mọc lên giữa các nền văn minh.
Trong nhiều thiên niên kỷ, nhân loại chưa bao giờ ngừng khao khát khôi phục lại “sự thống nhất đã mất” này. Ngày nay, trong bối cảnh trí tuệ nhân tạo có những tiến bộ nhanh chóng, chúng tôi đang sử dụng mã để xây dựng lại cầu nối giữa các ngôn ngữ. Hệ sinh thái dịch thuật được hỗ trợ bởi AI đang trỗi dậy từ tàn tích Babel. Tuy nhiên, việc xây dựng tòa tháp kỹ thuật số này không hề dễ dàng. Mọi thách thức trong việc đạt được bản dịch đa ngôn ngữ chính xác và phù hợp với ngữ cảnh đều kiểm tra chuyên môn của người xây dựng.
Bài viết này tập trung vào dịch đa ngôn ngữ, rút ra từ kinh nghiệm thực tế của ZStack để cung cấp phần giới thiệu chuyên sâu về quá trình triển khai thành công Nền tảng dịch đa ngôn ngữ ZStack AI, từ triển khai và tinh chỉnh mô hình cục bộ, đến phương pháp thiết kế nền tảng và những thách thức gặp phải. Để hiểu rõ hơn về kịch bản dịch tiếng Trung-Anh, hãy tham khảo bài viết trước của chúng tôi: Nền tảng dịch thuật AI ZStack: Các phương pháp hay nhất để dịch tiếng Trung-Anh.
II. Triển khai và tinh chỉnh mô hình cục bộ
Giống như trường hợp sử dụng bản dịch tiếng Trung-Anh, việc xây dựng nền tảng dịch đa ngôn ngữ AI bắt đầu với một nền tảng vững chắc: triển khai và tinh chỉnh mô hình cục bộ. Mặc dù các mô hình ngôn ngữ lớn (LLM) vượt trội trong các nhiệm vụ dịch thuật nói chung nhưng chúng bộc lộ những hạn chế rõ ràng trong các lĩnh vực chuyên biệt, chẳng hạn như tài liệu về phần mềm điện toán đám mây, nơi chúng thường không nắm bắt được thuật ngữ cụ thể của từng miền, bối cảnh kỹ thuật và các quy ước về phong cách của công ty.
Để giải quyết vấn đề này, ZStack đã triển khai một mô hình tinh chỉnh phù hợp với đặc điểm sản phẩm và nguyên tắc về kiểu dáng của mình.
Quá trình tinh chỉnh và triển khai mô hình bao gồm năm bước chính:
1. Chuẩn bị dữ liệu
Để cân bằng giữa chất lượng và hiệu quả chi phí, ZStack đã thiết kế quy trình phát triển kho dữ liệu theo vòng lặp của con người: Lựa chọn ngôn ngữ nguồn → Lựa chọn văn bản nguồn → Cài đặt quy tắc → Dịch AI → Đánh giá con người.
1) Lựa chọn ngôn ngữ nguồn
Bằng cách tận dụng các phiên bản tiếng Anh và tiếng Trung giản thể hoàn thiện của mình, ZStack đã thiết lập các lộ trình dịch thuật khác biệt cho các ngôn ngữ mục tiêu khác nhau để đạt được sự cân bằng tối ưu giữa hiệu quả và độ chính xác:
Đường dẫn chính (EN → X): Sử dụng tiếng Anh làm ngôn ngữ nguồn cốt lõi cho tất cả các ngôn ngữ đích ngoại trừ tiếng Trung phồn thể. Cách tiếp cận này phù hợp hoàn toàn với các hệ thống thuật ngữ được tiêu chuẩn hóa toàn cầu, đảm bảo tính chính xác và nhất quán của các thuật ngữ kỹ thuật.
Đường dẫn đặc biệt (ZH-CN → ZH-TW): Sử dụng tiếng Trung giản thể làm ngôn ngữ nguồn cho tiếng Trung phồn thể. Việc chuyển đổi trực tiếp này tận dụng ánh xạ ký tự gần một-một giữa hai biến thể, mang lại hiệu quả dịch thuật cao.
2) Lựa chọn văn bản nguồn
Để đảm bảo phạm vi bao phủ rộng rãi trong các tình huống dịch, ZStack đã tuyển chọn và cân bằng một cách có hệ thống các nguồn kho văn bản của mình:
Văn bản giao diện người dùng sản phẩm: Không ít hơn 50%. Bao gồm các tham số UI, thông báo nhắc nhở, văn bản điều hướng menu, v.v.
Tài liệu kỹ thuật sản phẩm: Khoảng 40%. Bao gồm hướng dẫn sử dụng, sách trắng kỹ thuật, hướng dẫn, v.v.
Vật liệu khác: Khoảng 10%. Bao gồm các tài liệu tiếp thị, tài liệu nội bộ, v.v.
3) Cài đặt quy tắc + Dịch AI
Để nhanh chóng xây dựng một kho dữ liệu quy mô lớn, ZStack đã áp dụng “ràng buộc về quy tắc, được hỗ trợ bởi AI” cách tiếp cận, sử dụng LLM nguồn mở để thực hiện bản dịch ban đầu hàng loạt, được hướng dẫn bởi các thuật ngữ được tuyển chọn thủ công và hướng dẫn về văn phong. Điều này cải thiện đáng kể hiệu quả sản xuất trong khi vẫn duy trì mức cơ bản về chất lượng.
4) Đánh giá con người
Người đánh giá đã đánh giá các bản dịch do AI tạo ra. Chỉ những kết quả đầu ra đáp ứng tiêu chuẩn chất lượng mới được chính thức thêm vào kho dữ liệu; một số khác đã được sửa hoặc loại bỏ. Điều này đảm bảo độ chính xác và độ tin cậy của kho dữ liệu cuối cùng.
2. Lựa chọn mô hình
ZStack đã chọn Qwen2.5-7B-Instruct làm mô hình cơ sở. Nhu cầu tính toán vừa phải, khả năng xử lý đa ngôn ngữ mạnh mẽ và khả năng mở rộng kiến trúc khiến nó rất phù hợp để đáp ứng các yêu cầu về hiệu suất và hiệu quả chi phí khi triển khai cục bộ cấp doanh nghiệp.
3. Tinh chỉnh mô hình
Bằng cách sử dụng kho dữ liệu đã chuẩn bị sẵn, ZStack đã tinh chỉnh mô hình bằng cách sử dụng công nghệ LoRA (Thích ứng cấp thấp).
4. Đánh giá mô hình
ZStack đã sử dụng một hệ thống đánh giá kết hợp kết hợp các chỉ số định lượng (BLEU, TER, COMET) với đánh giá của con người, đánh giá chất lượng bản dịch trên nhiều khía cạnh, bao gồm tính nhất quán về ngữ nghĩa, độ tương tự về văn bản, tính tuân thủ về văn phong, tính mạch lạc logic và tính trôi chảy.
5. Lặp lại mô hình
Để thích ứng với nhu cầu kinh doanh ngày càng phát triển và liên tục cải thiện khả năng của mô hình, ZStack triển khai một chu trình liên tục cập nhật kho dữ liệu và tinh chỉnh mô hình định kỳ. Các bản dịch chất lượng cao được tạo trong quá trình sản xuất sẽ được đưa trở lại vào kho dữ liệu và mô hình được đào tạo lại và đánh giá định kỳ bằng cách sử dụng dữ liệu cập nhật.
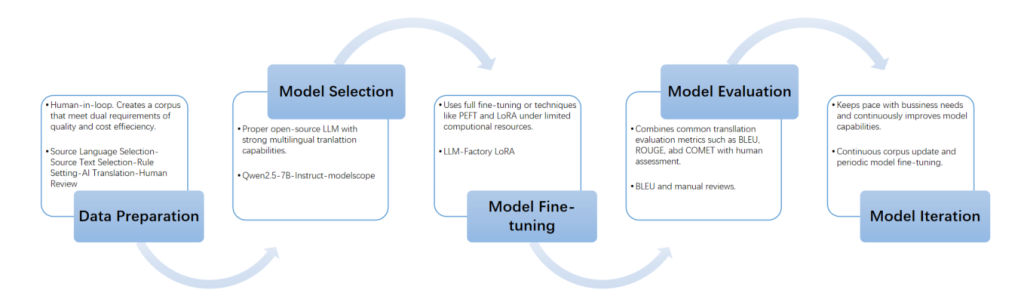
Hình 1. Năm bước chính của tinh chỉnh LLM
III. Phương pháp thiết kế nền tảng
Nền tảng dịch thuật đa ngôn ngữ ZStack AI được xây dựng trên ZStack AIOS và tận dụng các khả năng quản lý cơ sở hạ tầng AI của nó, chẳng hạn như tinh chỉnh và triển khai mô hình, để cung cấp các dịch vụ quản lý dịch thuật một cửa, bao gồm dịch giao diện người dùng sản phẩm, dịch tệp, quản lý bảng thuật ngữ/tập tài liệu, ghi nhật ký và kiểm tra cũng như quản lý hệ thống. Ngoài ra, nền tảng này cung cấp các API được tiêu chuẩn hóa để mở rộng khả năng dịch sang các ứng dụng bên ngoài.
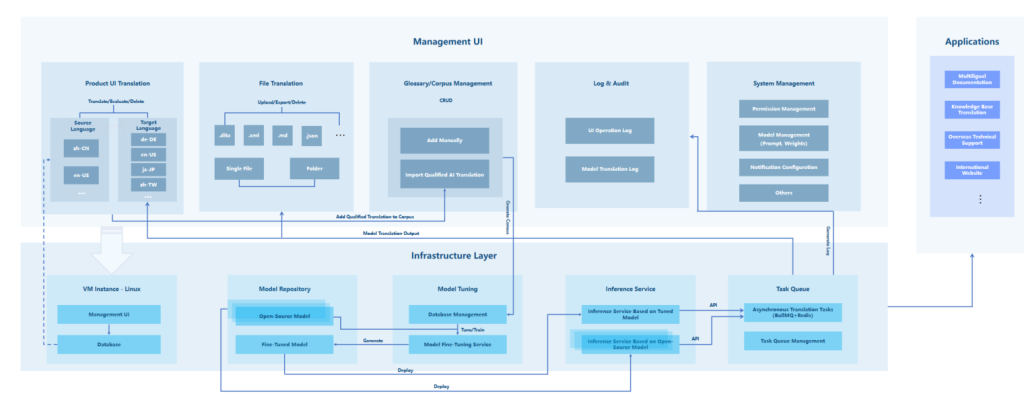
Hình 2. Khung thiết kế tổng thể
1. Lớp cơ sở hạ tầng
1) Quản lý mô hình: ZStack AIOS cung cấp quy trình quản lý cơ sở hạ tầng AI thống nhất, từ tinh chỉnh mô hình đến đánh giá và triển khai cho Nền tảng dịch đa ngôn ngữ ZStack AI.
2) Cơ sở dữ liệu: Áp dụng kiến trúc công cụ kép kết hợp PostgreSQL và Redis. PostgreSQL duy trì dữ liệu dịch cốt lõi để đảm bảo độ chính xác và độ tin cậy. Redis lưu trữ các kết quả dịch được truy cập thường xuyên để cải thiện hiệu quả dịch.
3) Khung dịch vụ: Phần phụ trợ được xây dựng trên NestJS, TypeORM và GraphQL, cho phép các API hiệu suất cao có hỗ trợ cho phân trang, lọc và thao tác hàng loạt. Giao diện người dùng sử dụng React 19, Zustand và Tailwind CSS để cung cấp giao diện người dùng quản lý toàn diện.
4) Tác vụ không đồng bộ: Sử dụng hàng đợi BullMQ để cho phép lập lịch và thực hiện các tác vụ dịch có tính sẵn sàng cao và tự động.
5) Tính toán băm: Được sử dụng chủ yếu trong các bản dịch giao diện người dùng sản phẩm. Mô-đun này áp dụng thuật toán MurmurHash (32 bit) để tạo hàm băm 64 bit cho mỗi mục nhập giao diện người dùng dựa trên khóa, giá trị văn bản nguồn và giá trị muối. Trình kích hoạt PostgreSQL giám sát các thay đổi về hàm băm. Sau khi phát hiện thấy thay đổi, hệ thống sẽ tự động bắt đầu quy trình dịch.
2. Lớp tính năng cốt lõi
1) Các tính năng cốt lõi
Dịch giao diện người dùng sản phẩm: Cho phép quy trình làm việc hoàn toàn tự động, từ đầu đến cuối để dịch văn bản giao diện người dùng, từ phát hiện thay đổi văn bản nguồn đến dịch và tích hợp kết quả vào kho lưu trữ mã.
Dịch tập tin: Hỗ trợ dịch tệp đơn lẻ và tệp hàng loạt ở nhiều định dạng, với chức năng xem trước và theo dõi tiến trình theo thời gian thực.
Thuật ngữ/Quản lý kho dữ liệu: Hỗ trợ tạo, xóa, cập nhật và truy vấn các thuật ngữ và kho văn bản.
Ghi nhật ký & Kiểm tra: Cung cấp nhật ký hoạt động nền tảng toàn diện.
Quản lý hệ thống: Hỗ trợ cấu hình quyền, lời nhắc và trọng lượng của mô hình cũng như cài đặt thông báo.
2) Thành phần kỹ thuật cốt lõi
Quy trình dịch tự động
*Xếp hàng nhiệm vụ: Phát hiện các thay đổi của văn bản nguồn thông qua so sánh hàm băm và xếp các tác vụ vào hàng đợi trong BullMQ. Mỗi tác vụ được gán một ID duy nhất và tính năng chống trùng lặp dựa trên Redis đảm bảo tính bình thường và ngăn chặn việc xử lý trùng lặp.
*Thực hiện dịch thuật: Truy xuất các tác vụ từ BullMQ và kiểm tra xem có bản dịch tương ứng được lưu trữ trong Redis hoặc PostgreSQL hay không. Nếu tìm thấy kết quả phù hợp, kết quả đó sẽ được sử dụng lại trực tiếp; mặt khác, nền tảng gọi các API mô hình để dịch và lưu trữ kết quả đầu ra trong Redis và PostgreSQL để sử dụng trong tương lai.
*Trước/Sau xử lý: Thực hiện xử lý trước/sau, bao gồm bảo vệ phần giữ chỗ, thay thế thuật ngữ bắt buộc dựa trên bảng thuật ngữ được tuyển chọn, xác thực dấu câu và tính điểm tự động. Các bản dịch có điểm thấp sẽ được chuyển tiếp để xem xét/sửa đổi thủ công nhằm đảm bảo chất lượng cuối cùng.
Quản lý khóa & dịch thuật: Sử dụng bảng KeyEntry để quản lý dữ liệu ngôn ngữ nguồn và bảng Dịch để quản lý dữ liệu ngôn ngữ đích. Hỗ trợ nhập văn bản nguồn hàng loạt, dịch tự động và xuất kết quả, với các chiến lược giải quyết xung đột (giữ, ghi đè, hợp nhất) trong quá trình cập nhật.
Bộ nhớ dịch: Lưu trữ các bản dịch và gói ngôn ngữ được sử dụng thường xuyên trong Redis, đồng thời triển khai các chiến lược nhận biết phiên bản để ngăn chặn tình trạng đóng dấu bộ nhớ đệm, cải thiện đáng kể hiệu quả cho việc dịch nội dung lặp đi lặp lại và giảm chi phí.
Giám sát và kiểm tra hàng đợi: Trực quan hóa trạng thái tác vụ dịch thông qua bảng điều khiển Giao diện người dùng BullMQ, đồng thời ghi lại thời gian và chi phí của các số liệu trong bảng JobAudit để phân tích hiệu suất và tối ưu hóa chi phí.
3. Lớp giao diện ứng dụng
Hiển thị các API được tiêu chuẩn hóa để cho phép tích hợp với các hệ thống kinh doanh bên trong và bên ngoài, cung cấp khả năng dịch cho các ứng dụng mở rộng như tài liệu đa ngôn ngữ, dịch cơ sở kiến thức, hỗ trợ kỹ thuật ở nước ngoài và phát triển trang web quốc tế.
IV. Những thách thức và giải pháp
1. Độ chính xác của bản dịch
Như đã đề cập ở trên, LLM có mục đích chung phải đối mặt với những thách thức đáng kể trong các tình huống dịch thuật phức tạp. Họ thường gặp khó khăn với sự mơ hồ về nghĩa của từ, ngữ cảnh không đầy đủ cũng như sự khác biệt về văn hóa và không cung cấp được bản dịch đủ tiêu chuẩn. Điều này đặc biệt rõ ràng trong các lĩnh vực chuyên biệt, trong đó sự không nhất quán về thuật ngữ và sự thiếu chính xác về ngữ nghĩa có thể gây ra các vấn đề nghiêm trọng về chất lượng.
Để giải quyết những vấn đề này, ZStack đã thiết lập một hệ thống quản lý bảng thuật ngữ toàn diện. Hệ thống này xác định các bản dịch được tiêu chuẩn hóa cho các thuật ngữ kỹ thuật, cùng với siêu dữ liệu theo ngữ cảnh phong phú, chẳng hạn như đường dẫn tệp, ví dụ sử dụng và nhãn miền, để hướng dẫn mô hình đạt được kết quả đầu ra chính xác và nhất quán.
Ngoài ra, nền tảng này còn giới thiệu tính năng bảo vệ giữ chỗ trong giai đoạn tiền xử lý để ngăn chặn lỗi định dạng và xác thực định dạng cũng như phân tích tỷ lệ trúng thuật ngữ trong giai đoạn xử lý hậu kỳ nhằm đảm bảo tính toàn vẹn về mặt kỹ thuật và tuân thủ các nguyên tắc về văn phong.
Để đảm bảo hơn nữa chất lượng đầu ra, ZStack sử dụng cơ chế chấm điểm tự động để đánh giá các bản dịch do AI tạo bằng cách sử dụng điểm BLEU và các chỉ số dựa trên quy tắc tùy chỉnh. Các bản dịch nằm dưới ngưỡng xác định trước sẽ tự động được chuyển đến người đánh giá để xác minh hoặc sàng lọc. Quy trình làm việc khép kín này, kết hợp việc tạo AI với sự giám sát của con người, cho phép cải thiện liên tục chất lượng dịch thuật theo thời gian.
2. Kiểm soát chi phí
Các bản cập nhật quy mô lớn cho nội dung nguồn có thể kích hoạt các tác vụ dịch AI khổng lồ, khiến số lượng lệnh gọi API tăng mạnh. Vì các dịch vụ AI thường tính phí theo mã thông báo nên điều này dẫn đến áp lực chi phí đáng kể. Ngoài ra, các thành phần cơ sở hạ tầng như Redis và BullMQ có thể trở thành nút thắt cổ chai khi hoạt động đồng thời ở mức cao, ảnh hưởng tiêu cực đến hiệu suất tổng thể và trải nghiệm người dùng.
Chìa khóa của việc tối ưu hóa chi phí nằm ở bộ nhớ đệm thông minh và khả năng loại bỏ trùng lặp tác vụ. Bằng cách tận dụng Redis để lưu vào bộ nhớ đệm hiệu quả và triển khai các cơ chế chống trùng lặp của BullMQ, nền tảng này đã giảm đáng kể các tác vụ dịch dư thừa và các lệnh gọi API không cần thiết. Thiết kế này không chỉ giúp giảm chi phí mà còn cải thiện tốc độ phản hồi của hệ thống.
Ngoài ra, để đảm bảo độ tin cậy của dịch vụ, nền tảng này sử dụng chuỗi dự phòng nhiều nhà cung cấp LLM và giới hạn tốc độ thông minh để kiểm soát tần suất lệnh gọi API trong khi vẫn đảm bảo tính khả dụng của dịch vụ. Nó cũng hỗ trợ triển khai các LLM cục bộ tự lưu trữ (ví dụ: Llama) để giảm sự phụ thuộc vào API bên ngoài, cho phép phát triển bền vững và kiểm soát chi phí.
3. Quản lý tác vụ
Các môi trường có tính đồng thời cao gây ra các rủi ro như tồn đọng công việc BullMQ, sự cố quy trình của nhân viên và việc thực thi nhiệm vụ trùng lặp, dẫn đến lãng phí tài nguyên và tiềm ẩn sự không nhất quán về dữ liệu. Việc xử lý hàng đợi thư chết (DLQ) làm tăng thêm độ phức tạp, đòi hỏi phải có thiết kế mạnh mẽ để duy trì sự ổn định của hệ thống.
Giải pháp tập trung vào sự thiếu năng lực. Nền tảng sử dụng Khóa phân phối Redis (RedLock) để đảm bảo rằng mỗi tác vụ được thực thi chính xác một lần và đặt giới hạn thử lại tác vụ (tối đa 5 lần thử) để ngăn chặn số lần thử lại vô hạn. Các tác vụ không thành công sẽ tự động được chuyển đến DLQ để phân tích và xử lý sau. Thiết kế này đảm bảo tính nhất quán của dữ liệu ngay cả trong điều kiện đặc biệt.
Giới hạn và giám sát tốc độ thông minh cũng đóng vai trò trong quản lý tác vụ. Nền tảng này sử dụng các tính năng Giới hạn tỷ lệ và nhóm của BullMQ để triển khai điều tiết chi tiết theo các dự án kinh doanh và nhà cung cấp LLM. Nó thiết lập một cơ chế giám sát độ dài hàng đợi: khi các tác vụ đang chờ xử lý vượt quá 100, cảnh báo sẽ được kích hoạt. Hệ thống giám sát và cảnh báo này giúp phát hiện, chẩn đoán và khắc phục lỗi nhanh chóng.
4. Xung đột băm
Trong các hệ thống dịch thuật quy mô lớn, cách tạo khóa bộ nhớ đệm duy nhất và hiệu quả là một thách thức kỹ thuật quan trọng. Việc nối chuỗi đơn giản hoặc các thuật toán băm cơ bản dễ bị xung đột, dẫn đến việc vô hiệu hóa bộ đệm hoặc đánh giá sai tác vụ dịch, ảnh hưởng nghiêm trọng đến hiệu suất hệ thống và độ chính xác của bản dịch.
Để giải quyết vấn đề này, nền tảng sử dụng thuật toán MurmurHash (32-bit) để tạo giá trị băm dựa trên giá trị văn bản nguồn và Khóa của mục nhập giao diện người dùng. So với các thuật toán chuỗi MD5 hoặc SHA, thuật toán này cung cấp tốc độ tính toán nhanh hơn, khiến thuật toán phù hợp hơn với các tình huống lưu vào bộ nhớ đệm tần suất cao. Nó cũng hoạt động xuất sắc trên các tập dữ liệu lớn, tránh được các vấn đề xung đột băm phổ biến một cách hiệu quả.
Một tối ưu hóa hơn nữa là băm kép. Nền tảng này sử dụng các giá trị muối khác nhau để tạo ra hai giá trị băm 32 bit riêng biệt, sau đó ghép 32 bit cao và 32 bit thấp để tạo thành hàm băm 64 bit cuối cùng. Điều này làm giảm đáng kể khả năng xảy ra xung đột và cải thiện độ chính xác của lần truy cập bộ nhớ đệm. Không gian băm 64 bit này hỗ trợ nhiều giá trị, đưa xác suất xung đột xuống mức gần như không đáng kể.
Bằng cách kết hợp hàm băm này với cơ chế phát hiện thay đổi theo thời gian thực, nền tảng đảm bảo rằng dịch thuật AI chỉ được kích hoạt khi xảy ra thay đổi nội dung có ý nghĩa—tránh xử lý không cần thiết do các chỉnh sửa tầm thường (ví dụ: điều chỉnh khoảng trắng). Điều này cải thiện đáng kể hiệu quả và bảo tồn tài nguyên tính toán.
5. Bài học từ thực tiễn
Bằng cách giải quyết một cách có hệ thống bốn thách thức cốt lõi—độ chính xác của bản dịch, kiểm soát chi phí, quản lý tác vụ và xung đột băm—ZStack đã xây dựng thành công nền tảng dịch thuật đa ngôn ngữ AI hiệu quả, ổn định và tiết kiệm chi phí. Các giải pháp được mô tả không chỉ có thể áp dụng cho nhóm công nghệ hiện tại mà còn đặt nền tảng vững chắc cho việc phát triển hệ thống trong tương lai.
Trong quá trình triển khai, bạn nên sử dụng chiến lược tối ưu hóa gia tăng: ưu tiên giải quyết các vấn đề ảnh hưởng nhiều nhất đến trải nghiệm người dùng, sau đó tinh chỉnh dần các khía cạnh khác của hệ thống. Thông qua việc sàng lọc liên tục, hệ thống cuối cùng có thể đạt được hiệu suất tối ưu. Trên thực tế, các giải pháp cho từng thách thức kỹ thuật được kết nối với nhau, tạo thành một hệ sinh thái kỹ thuật hoàn chỉnh nhằm đảm bảo sự ổn định của toàn bộ hệ thống trong môi trường sản xuất phức tạp.
V. Giá trị nền tảng
1. Quản lý thống nhất: Trực quan và hiệu quả
Nền tảng dịch thuật đa ngôn ngữ ZStack AI cung cấp giao diện quản lý trực quan thống nhất, cung cấp hỗ trợ toàn diện cho quản lý tập tin, dịch giao diện người dùng sản phẩm, dịch tệp, ghi nhật ký & kiểm tra cũng như các cài đặt hệ thống như quản lý quyền, cấu hình mô hình và cài đặt thông báo.
![]()
Hình 3. Giao diện dịch UI sản phẩm
![]()
Hình 4. Giao diện dịch tập tin
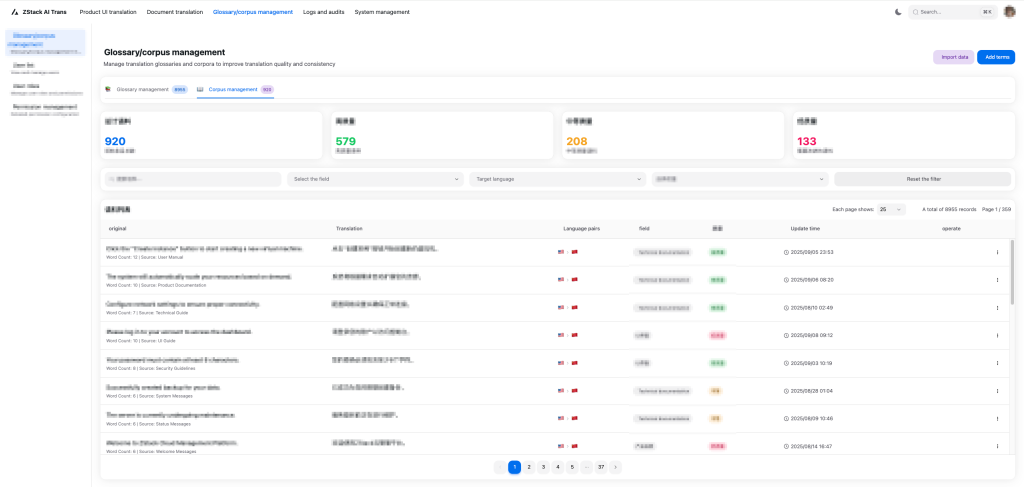
Hình 5. Giao diện quản lý Corpus
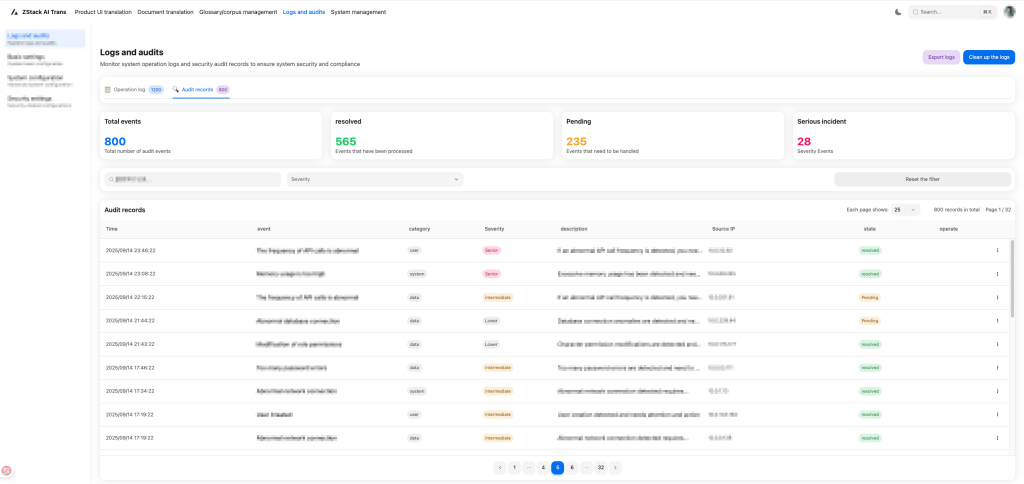
Hình 6. Giao diện đăng nhập và kiểm tra
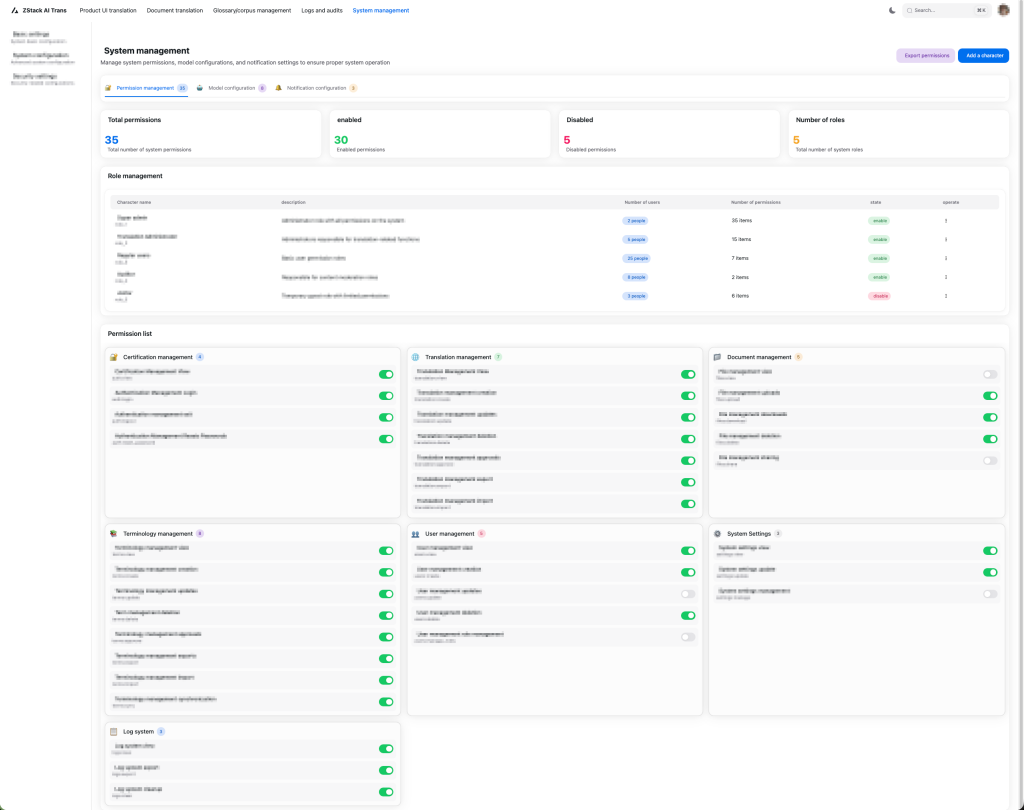
Hình 7. Giao diện quản lý quyền
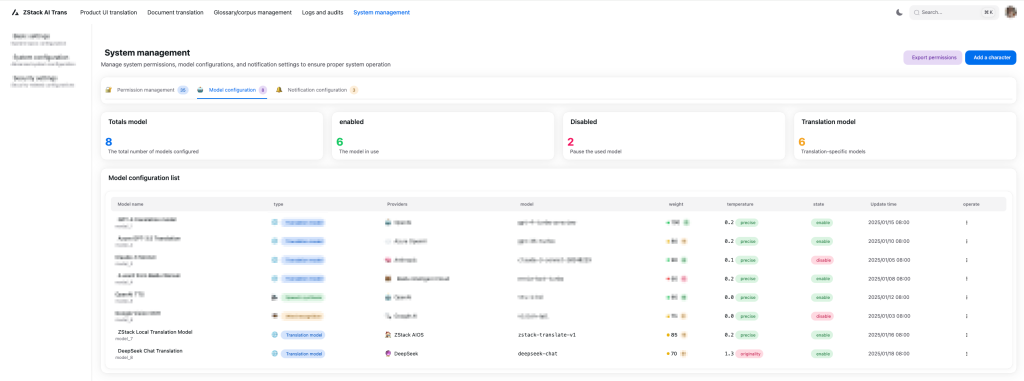
Hình 8. Giao diện cấu hình mô hình
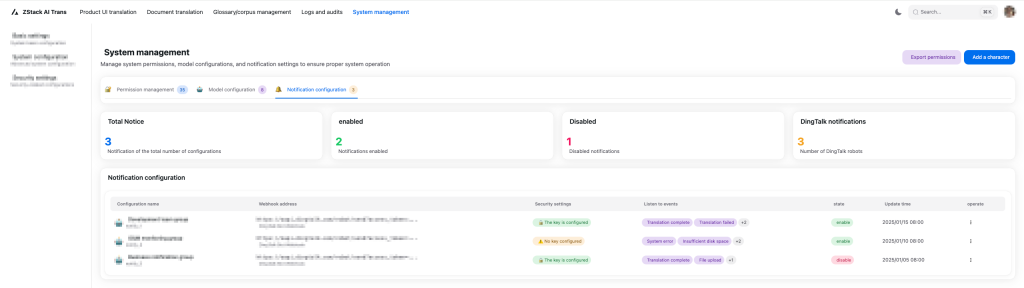
Hình 9. Giao diện cấu hình thông báo
2. Khả năng mở rộng linh hoạt: Mở rộng và trao quyền
Nền tảng dịch thuật đa ngôn ngữ AI của ZStack cung cấp các API được tiêu chuẩn hóa cho phép tích hợp liền mạch với nhiều hệ thống kinh doanh khác nhau, chẳng hạn như cơ sở kiến thức nội bộ, hệ thống hỗ trợ kỹ thuật ở nước ngoài và các trang web quốc tế, cho phép toàn doanh nghiệp truy cập vào khả năng dịch thuật do AI cung cấp.
VI. Kết luận
Để giải quyết những thách thức của toàn cầu hóa, ZStack Documentation đang nâng tầm công nghệ dịch thuật chuyên nghiệp thông qua sự đổi mới liên tục. Chúng tôi mong muốn được cộng tác với nhiều đối tác khác trong ngành để cùng nhau định hình tương lai của hệ sinh thái dịch thuật thông minh do AI điều khiển. Giấc mơ của Babel vẫn tiếp tục.