Nền tảng đám mây ZStack
Triển khai một máy chủ với đầy đủ tính năng, miễn phí trong một năm

Tài liệu và công cụ sản phẩm toàn diện

Đề cao giá trị của Khách hàng là trên hết và sứ mệnh Phục vụ Khách hàng, ZStack tận tâm cung cấp các dịch vụ an toàn và ổn định cho khách hàng.

Để giáo dục các đối tác của ZStack và những cá nhân quan tâm về điện toán đám mây và trau dồi tài năng về điện toán đám mây.

ZStack cung cấp cơ sở hạ tầng đám mây sáng tạo cho mười ngành công nghiệp chính

Thông qua ba phần chính, hàng chục ngàn từ và hơn 10 khách hàng đại diện toàn cầu
I. Giới thiệu
Trong bối cảnh kinh doanh toàn cầu hóa ngày nay, các doanh nghiệp mở rộng ra nước ngoài cần có sự hỗ trợ dịch thuật chất lượng cao cho giao diện người dùng sản phẩm, tài liệu kỹ thuật, tài liệu tiếp thị và nội dung khác được điều chỉnh cho phù hợp với thị trường mục tiêu. Khi công nghệ AI tiến bộ, các doanh nghiệp phải đối mặt với những thách thức quan trọng: Làm cách nào để tận dụng AI để nâng cao chất lượng dịch thuật? Làm cách nào để chuẩn hóa quy trình dịch thuật thành chuỗi công cụ? Và làm thế nào có thể xây dựng được một hệ thống đánh giá chất lượng thực tế?
Bài viết này tập trung vào bản dịch tiếng Trung-Anh, rút ra từ thực tiễn tài liệu của ZStack để cung cấp thông tin khám phá chuyên sâu về việc triển khai và tinh chỉnh các mô hình địa phương, triết lý thiết kế đằng sau nền tảng dịch thuật AI một cửa và những thách thức gặp phải trong quá trình triển khai. Để biết thông tin chi tiết về các tình huống dịch đa ngôn ngữ, hãy theo dõi các cập nhật trong tương lai trên tài khoản chính thức của chúng tôi.
II. Triển khai và tinh chỉnh mô hình cục bộ
Các Mô hình ngôn ngữ lớn (LLM) như ChatGPT vượt trội trong các nhiệm vụ dịch thuật nói chung. Tận dụng phương pháp học tập nhanh chóng và kỹ thuật nhanh chóng, LLM vượt trội hơn các hệ thống dịch máy truyền thống về khả năng hiểu trôi chảy và ngữ cảnh cho hầu hết các nhu cầu ngôn ngữ hàng ngày.
Tuy nhiên, các LLM chung này cho thấy những hạn chế rõ ràng khi áp dụng cho các bản dịch kỹ thuật chuyên ngành, chẳng hạn như tài liệu điện toán đám mây, nơi chúng thường không nắm bắt được thuật ngữ và quy ước viết cụ thể của công ty.
![]()
Hình 1. Hạn chế của LLM chung trong dịch thuật
Để giải quyết những thách thức này, ZStack đã áp dụng cách tiếp cận “mô hình nền tảng + tinh chỉnh”, được cấu trúc theo năm bước chính để xây dựng khả năng dịch thuật chuyên nghiệp.
1. Chuẩn bị dữ liệu
Kết quả tinh chỉnh mô hình phụ thuộc rất nhiều vào chất lượng dữ liệu đào tạo. Để đảm bảo điều này, ZStack triển khai khung lựa chọn kho ngữ liệu nhiều tầng, được quản lý chặt chẽ, với phân phối nguồn cân bằng chiến lược: 50% tài liệu kỹ thuật cốt lõi (ví dụ: hướng dẫn sử dụng), ít nhất 40% chuỗi giao diện người dùng sản phẩm (ví dụ: lời nhắc giao diện) và 10% tài liệu hỗ trợ (ví dụ: hướng dẫn thực hành). Tất cả các tài liệu song ngữ phải vượt qua quá trình xác nhận nghiêm ngặt về độ chính xác của thuật ngữ, tính nhất quán về văn phong, chiều sâu kỹ thuật và phạm vi kịch bản.
2. Lựa chọn mô hình
ZStack đã chọn mô hình nguồn mở Qwen2.5-7B-Instruct làm mô hình nền tảng, cung cấp kích thước 7B cân bằng đồng thời vượt trội trong khả năng xử lý đa ngôn ngữ và khả năng mở rộng kiến trúc.
3. Tinh chỉnh mô hình
Các kỹ thuật như LoRA (Xếp hạng thấp) giúp tinh chỉnh hiệu quả. ZStack đã đào tạo mô hình chỉ bằng một GPU NVIDIA 3090, giúp cắt giảm đáng kể chi phí tính toán.
4. Đánh giá mô hình
Hệ thống đánh giá kết hợp các số liệu tự động (BLEU, ROUGE, COMET) với các đánh giá thủ công của các nhà văn kỹ thuật chuyên nghiệp người Anh để đánh giá chất lượng từ nhiều khía cạnh.
5. Lặp lại mô hình
Để điều chỉnh mô hình cho phù hợp với nhu cầu kinh doanh ngày càng phát triển, ZStack sử dụng chu kỳ cập nhật “3 + 1”: ba tháng để chuẩn bị cơ sở đào tạo và một tháng để điều chỉnh mô hình và kiểm tra chất lượng. Quy trình thường xuyên này cho phép chúng tôi liên tục cải thiện mô hình bằng cách thêm dữ liệu mới và hành động dựa trên phản hồi.
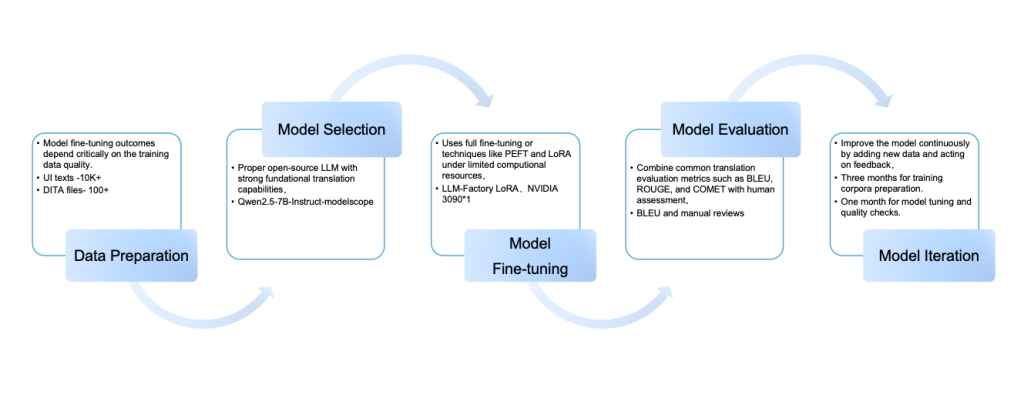
Hình 2. Năm bước chính của tinh chỉnh LLM
III. Nền tảng dịch thuật ZStack AI: Triết lý thiết kế
Thử thách tiếp theo là tích hợp liền mạch LLM đã được tinh chỉnh vào quy trình dịch thuật.
Nền tảng dịch thuật AI ZStack, được hỗ trợ bởi nền tảng ZStack AIOS, cung cấp giải pháp hoàn chỉnh từ cơ sở hạ tầng AI đến giao diện ứng dụng. Nó kết hợp kho văn bản chuyên dụng của ZStack với LLM được điều chỉnh tùy chỉnh để cung cấp khả năng quản lý dịch thuật tất cả trong một.
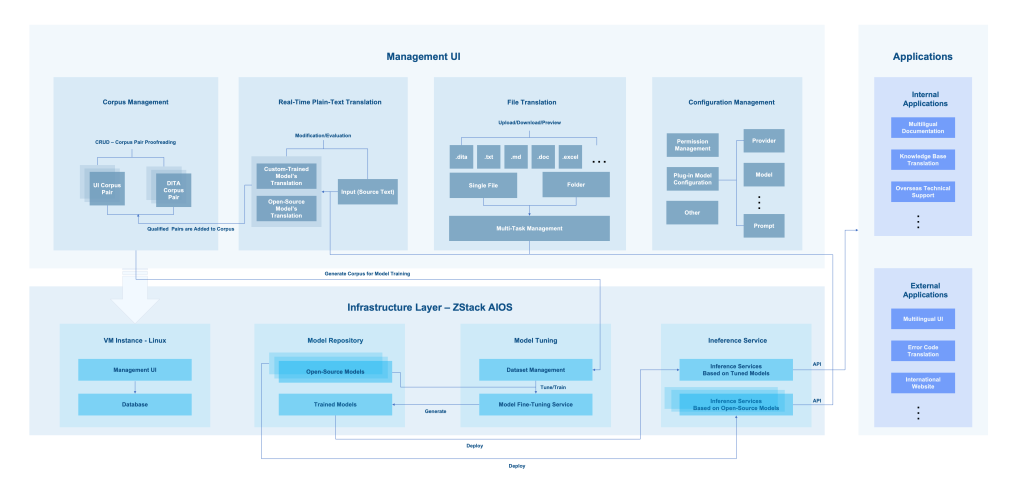
Hình 3. Khung thiết kế tổng thể
1. Lớp cơ sở hạ tầng
Lớp này tích hợp các thành phần thiết yếu:
Trung tâm mô hình: Lưu trữ và sắp xếp tất cả các mô hình AI, bao gồm các mô hình sẵn sàng sử dụng và mô hình tùy chỉnh.
Điều chỉnh không gian làm việc: Cho phép bạn tinh chỉnh các mô hình bằng cách sử dụng tập dữ liệu của riêng bạn.
Dịch vụ suy luận: Đưa các mô hình vào hoạt động sản xuất một cách nhanh chóng.
Quản lý dữ liệu: Cung cấp giao diện quản lý và dịch vụ cơ sở dữ liệu thông qua các phiên bản VM.
2. Lớp chức năng cốt lõi
Nền tảng này có bốn mô-đun cốt lõi:
Quản lý tập tin: Liên tục thu thập các nguồn tài liệu song ngữ chất lượng cao.
Dịch văn bản: Hỗ trợ các mô hình nội bộ và bên ngoài, với tính năng so sánh song song và thêm một cú nhấp chuột vào các bản dịch chất lượng cao vào kho văn bản. Dịch tệp: Dịch từng tệp hoặc nhiều tệp (.dita, .txt, .md, .doc, .xlsx, v.v.) với các tùy chọn xem trước và cập nhật tiến trình theo thời gian thực.
Cài đặt hệ thống: Cung cấp các điều khiển truy cập và tích hợp mô hình bên ngoài để linh hoạt.
3. Lớp giao diện ứng dụng
Kết nối các hệ thống bên trong và bên ngoài bằng API được tiêu chuẩn hóa.
Sử dụng nội bộ: Vé tài liệu, cơ sở tri thức, hỗ trợ ở nước ngoài.
Sử dụng bên ngoài: Dịch thuật UI sản phẩm, chuẩn hóa mã lỗi, website đa ngôn ngữ.
IV. Những thách thức và giải pháp thực hiện
1. Phân đoạn và tập hợp lại tài liệu DITA
Với khả năng vốn có của LLM trong việc xử lý nội dung có cấu trúc và phân cấp, ZStack áp dụng chiến lược bảo toàn định dạng khi xây dựng kho dữ liệu DITA để giữ lại đầy đủ cấu trúc nội dung gốc và thông tin đánh dấu của tài liệu DITA.
Không giống như quy trình dịch văn bản thuần truyền thống, phương pháp này giảm đáng kể nỗ lực xử lý hậu kỳ cho các thành phần và tham chiếu được định dạng, chẳng hạn như thẻ, giá trị thuộc tính và khối mã nhúng, từ đó giảm độ phức tạp của bản dịch tổng thể. Tuy nhiên, do giới hạn mã thông báo LLM, các tài liệu dài vẫn yêu cầu phân đoạn để tránh bị cắt bớt.
Vì bản dịch phụ thuộc nhiều vào ngữ cảnh nên ZStack chia nội dung DITA ở cấp độ đoạn văn để ngăn các từ bị cô lập hoặc các câu bị rời rạc.
Để đạt được điều này, ZStack đã phát triển một thuật toán phân đoạn thích ứng để chia các tài liệu DITA dài thành các phần mạch lạc về mặt ngữ nghĩa. Các đoạn này được xử lý tuần tự bởi LLM đã được đào tạo, với bản dịch được tập hợp lại theo cấu trúc.
2. Đảm bảo độ chính xác nhiều lớp
Do tính không chắc chắn cố hữu trong đầu ra LLM do tính chất xác suất của chúng và các yêu cầu nghiêm ngặt về định dạng giống như XML của tài liệu DITA, nền tảng này triển khai hệ thống đảm bảo chất lượng nhiều tầng để đảm bảo độ chính xác và độ tin cậy của bản dịch.
1) Kiểm soát chất lượng dữ liệu đào tạo
Chất lượng của dữ liệu huấn luyện ảnh hưởng trực tiếp đến việc mô hình hoạt động tốt như thế nào. Đó là lý do tại sao ZStack sử dụng cơ chế đảm bảo chất lượng gồm hai bước, kết hợp xem xét thủ công với sự hỗ trợ của AI. Những người viết kỹ thuật chuyên nghiệp xem xét tất cả các tài liệu đào tạo, trong khi các kỹ thuật tinh chỉnh hướng dẫn và kỹ thuật nhanh chóng giúp giữ cho kết quả đầu ra luôn rõ ràng. Điều này đảm bảo các bản dịch luôn tập trung, không có những giải thích hoặc tóm tắt không cần thiết.
2) Đảm bảo chất lượng đầu ra của mô hình
Để đảm bảo tính toàn vẹn của cấu trúc DITA, nền tảng áp dụng cơ chế thử lại thích ứng. Khi bản dịch không xác thực được XML, trước tiên nền tảng sẽ điều chỉnh các tham số của nó và xử lý lại nội dung. Nếu lỗi cấu trúc vẫn còn, nền tảng sẽ tiếp tục chia tệp nguồn thành các phân đoạn nhỏ hơn trước khi thử dịch lại. Trong những trường hợp hiếm hoi khi các phương pháp tiếp cận tiêu chuẩn không còn phù hợp, hệ thống sẽ tự động chuyển nhiệm vụ sang các mô hình quy mô lớn hơn. Để đảm bảo độ chính xác của nội dung DITA, nền tảng này sẽ sớm triển khai hệ thống kiểm tra chất lượng do AI cung cấp để cung cấp xác minh bổ sung về chất lượng dịch thuật.
3. Kỹ thuật nhanh chóng
Là một công việc có tính chuyên môn cao nên dịch tài liệu yêu cầu hệ thống phải xử lý đầu vào một cách chặt chẽ như nguồn dịch chứ không phải nội dung hội thoại. Trong quá trình đào tạo, chúng tôi sử dụng lời nhắc của hệ thống và tinh chỉnh hướng dẫn để điều chỉnh mô hình cho hành vi chỉ dịch, loại bỏ mọi xu hướng đối thoại. Đáng chú ý, ngay cả khi chỉ được đào tạo theo lời nhắc từ tiếng Trung sang tiếng Anh, mô hình vẫn duy trì độ chính xác cao trong việc hiểu hướng dẫn dịch từ tiếng Anh sang tiếng Trung trong quá trình suy luận.
Đào tạo và suy luận làm việc cùng nhau. Để tối đa hóa hiệu quả trong cả hai giai đoạn, điều quan trọng là giảm thiểu mức tiêu thụ mã thông báo trong lời nhắc hệ thống. ZStack phát triển kiến trúc nhắc nhở hợp lý nhưng toàn diện bao gồm các yếu tố chính như kiểu dịch, định dạng đầu ra và các quy tắc cụ thể. Điều này cho phép mô hình tìm hiểu dần dần các cấu hình ưu tiên trong quá trình đào tạo và mang lại kết quả mong đợi trong quá trình suy luận. Nhờ kiến thức nền tảng sâu rộng của mô hình, một số lời nhắc nhất định có thể vẫn đơn giản và tổng quát. Ví dụ: chỉ cần chỉ định “bảo toàn cấu trúc XML” thường đạt được kết quả mong muốn mà không cần hướng dẫn dài dòng.
V. Giá trị và lợi ích
1. Quản lý tập trung với các hoạt động trực quan
Nền tảng dịch thuật AI ZStack cung cấp giao diện quản lý trực quan thống nhất, cung cấp hỗ trợ toàn diện để duy trì kho dữ liệu đào tạo, thực hiện dịch văn bản theo thời gian thực, tạo tác vụ dịch tệp cũng như theo dõi tiến trình và kết quả dịch. Đối với các tác vụ dịch không thành công, người dùng có thể truy cập trực tiếp vào nhật ký tác vụ để nhanh chóng xác định vấn đề.
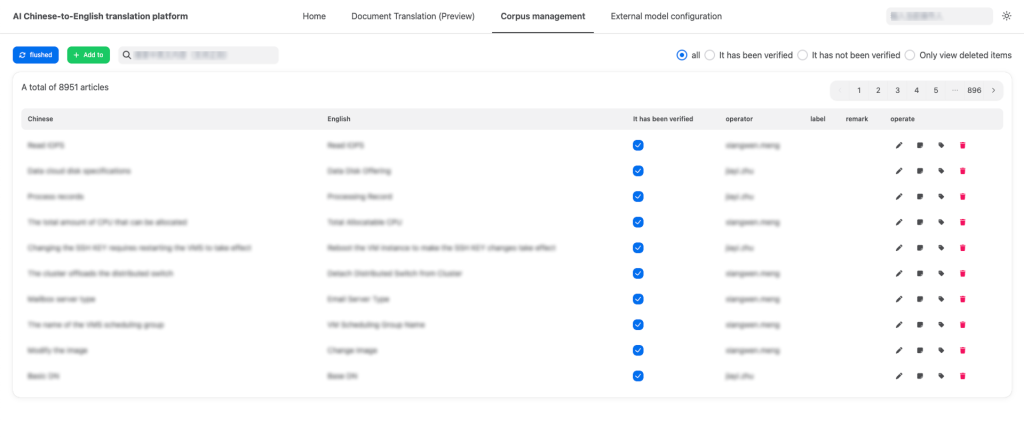
Hình 4. Giao diện quản lý Corpus
![]()
Hình 5. Giao diện dịch tệp
![]()
Hình 6. Xem trước bản dịch
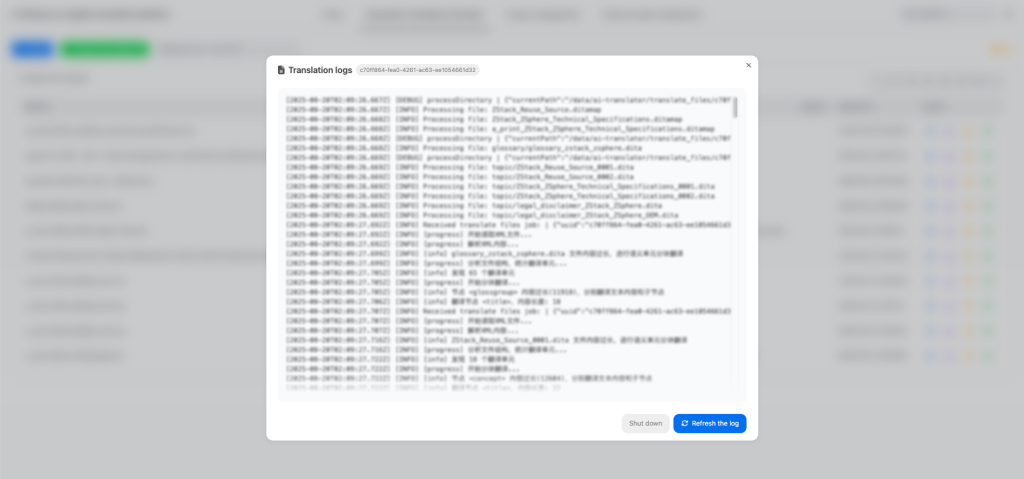
Hình 7. Xem nhật ký tác vụ
2. Tích hợp linh hoạt để nâng cao hiệu quả
Nền tảng dịch thuật AI ZStack cho phép tích hợp liền mạch với các hệ thống kinh doanh khác nhau thông qua các API được tiêu chuẩn hóa, cung cấp dịch vụ dưới dạng dịch vụ. Ví dụ: khi được kết nối với hệ thống i18n, nền tảng có thể dịch ngay văn bản giao diện người dùng của sản phẩm chỉ bằng một cú nhấp chuột. Kết hợp với kiểm tra chất lượng thủ công, điều này giúp tăng tốc đáng kể hiệu quả phân phối bản dịch giao diện người dùng.
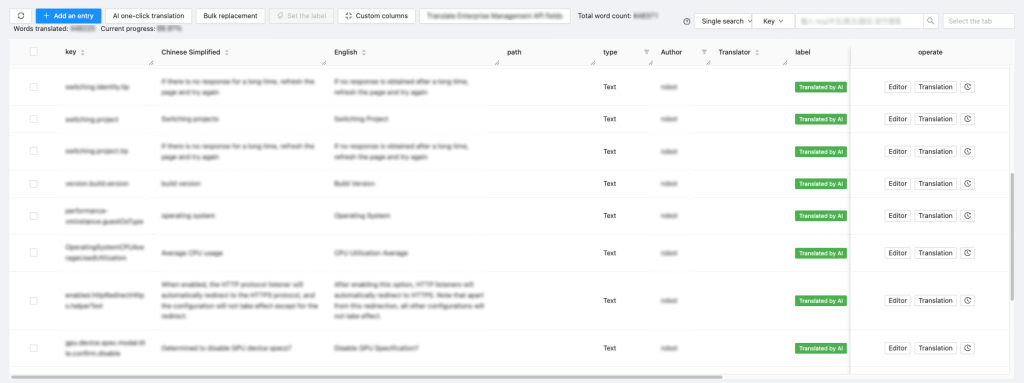
Hình 8. Tích hợp hệ thống i18n
VI. Lời kết
ZStack Documentation đã nỗ lực đổi mới và triển khai các công nghệ dịch thuật chuyên nghiệp để đáp ứng những thách thức toàn cầu hóa. Từ tinh chỉnh LLM đến xây dựng Nền tảng dịch thuật AI ZStack như một dịch vụ dịch thuật một cửa, chúng tôi đã cải thiện cả độ chính xác của bản dịch và kiến thức chuyên môn về miền cụ thể. Các giải pháp của chúng tôi có nguồn gốc sâu xa từ các tình huống kinh doanh thực tế, nơi chúng tôi đã chuẩn hóa thành công toàn bộ quy trình làm việc. Trong tương lai, chúng tôi mong muốn được cộng tác với nhiều đối tác khác trong ngành để cùng nhau phát triển công nghệ dịch thuật chuyên nghiệp.
Là một phần của hành trình này, chúng tôi rất vui được chia sẻ những hiểu biết sâu sắc của mình với cộng đồng toàn cầu. Sherrie Pan (Người quản lý tài liệu tại ZStack và đồng tác giả của bài viết này) sẽ trình bày phiên này “Từ Agile đến AI: Những thách thức và giải pháp cho tài liệu phần mềm doanh nghiệp” tại hội nghị tcworld 2025 ở Stuttgart, Đức, vào ngày 12 tháng 11 năm 2025. Hãy tham gia cùng chúng tôi để khám phá tương lai của tài liệu trong kỷ nguyên AI!
 2025-02-11
2025-02-11