Nền tảng đám mây ZStack
Triển khai một máy chủ với đầy đủ tính năng, miễn phí trong một năm

Tài liệu và công cụ sản phẩm toàn diện

Đề cao giá trị của Khách hàng là trên hết và sứ mệnh Phục vụ Khách hàng, ZStack tận tâm cung cấp các dịch vụ an toàn và ổn định cho khách hàng.

Để giáo dục các đối tác của ZStack và những cá nhân quan tâm về điện toán đám mây và trau dồi tài năng về điện toán đám mây.

ZStack cung cấp cơ sở hạ tầng đám mây sáng tạo cho mười ngành công nghiệp chính

Thông qua ba phần chính, hàng chục ngàn từ và hơn 10 khách hàng đại diện toàn cầu
Lĩnh vực trí tuệ nhân tạo không ngừng mở rộng mỗi ngày. Các công ty hiện cần một cơ sở hạ tầng AI vững chắc và linh hoạt để xử lý khối lượng công việc AI nặng mà không gặp vấn đề gì. Nhu cầu đào tạo và chạy các mô hình lớn tăng nhanh, đặc biệt là trong thiết lập đám mây. Bí quyết thực sự để theo kịp nằm ở việc quản lý tài nguyên máy tính một cách thông minh. Lên lịch GPU, tối ưu hóa GPU, lập lịch khối lượng công việc, tự động điều chỉnh quy mô cụm và song song mô hình, tất cả đều phối hợp với nhau để biến điều này thành hiện thực. Trong bài viết này, chúng ta sẽ xem xét các bước thực tế để tạo ra một cơ sở hạ tầng AI thông minh hỗ trợ điện toán đám mây đa GPU và giải quyết các thách thức chung về tài nguyên.
Một ngăn xếp cơ sở hạ tầng AI bao gồm một số lớp được kết nối. Mỗi lớp hỗ trợ các nhu cầu cụ thể của nhiệm vụ AI. Tài nguyên GPU nằm ở trung tâm vì quá trình đào tạo và suy luận phụ thuộc rất nhiều vào chúng. Hệ thống lưu trữ, mạng nhanh và công cụ quản lý thông minh đều phải kết hợp với nhau một cách trơn tru. Một ngăn xếp được thiết kế tốt bao gồm các tính năng lập lịch mạnh mẽ. Các tính năng này phân phối công việc trên các GPU một cách khôn ngoan, giảm thời gian chờ đợi và đảm bảo mọi tài nguyên luôn bận rộn và hiệu quả.
Lập kế hoạch GPU quyết định công việc nào sẽ chạy trên GPU nào và khi nào. Trong các dự án AI, việc lập kế hoạch tốt sẽ ngăn ngừa sự chậm trễ kéo dài và kiểm soát chi phí. Khi việc lên lịch hoạt động kém, một số GPU không hoạt động trong khi những GPU khác phải vật lộn với quá nhiều công việc. Sự mất cân bằng này làm mọi thứ chậm lại và làm tăng hóa đơn. Thuật toán lập kế hoạch thông minh cân bằng tải hợp lý. Chúng cung cấp cho mỗi GPU khối lượng công việc phù hợp để quá trình đào tạo kết thúc nhanh hơn và phần cứng mang lại giá trị tối đa.
Các công ty hiện cần một giải pháp cơ sở hạ tầng vững chắc và linh hoạt cho điện toán đám mây đa GPU để xử lý khối lượng công việc AI nặng mà không gặp vấn đề gì. Họ cần những hệ thống sử dụng những chiếc thẻ đắt tiền này theo cách tốt nhất có thể. Lên lịch GPU thông minh, cùng với bộ chia tỷ lệ tự động theo cụm và mô hình song song, đảm bảo cơ sở hạ tầng phát triển hoặc thu hẹp chính xác khi được yêu cầu. Kết quả là một nền tảng có thể xử lý các công việc ngày nay và các mô hình lớn hơn trong tương lai mà không cần tốn thêm công sức.
Lập kế hoạch GPU quyết định công việc nào sẽ chạy trên GPU nào và khi nào. Trong các dự án AI, việc lập kế hoạch tốt sẽ ngăn ngừa sự chậm trễ kéo dài và kiểm soát chi phí. Khi việc lên lịch hoạt động kém, một số GPU không hoạt động trong khi những GPU khác phải vật lộn với quá nhiều công việc. Sự mất cân bằng này làm mọi thứ chậm lại và làm tăng hóa đơn. Tin tức lập lịch GPU thường thảo luận về cách các thuật toán lập lịch GPU thông minh cân bằng tải hợp lý. Chúng cung cấp cho mỗi GPU khối lượng công việc phù hợp để quá trình đào tạo kết thúc nhanh hơn và phần cứng mang lại giá trị tối đa. Ngăn xếp AI được thiết kế tốt tận dụng các chiến lược lập kế hoạch nâng cao để quản lý tài nguyên một cách hiệu quả.
Trong nền tảng đám mây dùng chung, nhiều người dùng hoặc nhóm cần quyền truy cập GPU cùng một lúc. Chia sẻ GPU giải quyết thách thức này một cách rõ ràng. Các công nghệ như MIG (GPU đa phiên bản) cho phép nhiều khối lượng công việc chạy trên một thẻ vật lý một cách an toàn. Mỗi nhiệm vụ đều có phần được bảo vệ riêng nên không có gì cản trở. Khi GPU chia sẻ việc lập lịch khối lượng công việc, nền tảng sẽ chỉ định tài nguyên dựa trên mức độ ưu tiên và mức độ khẩn cấp thực sự. Các nhóm có được hiệu suất cao trong khi công ty chi tiêu ít hơn cho phần cứng.
Các mô hình AI hiện đại ngày càng lớn hơn và phức tạp hơn. Đó là lý do tại sao việc tối ưu hóa GPU và tính song song của mô hình lại quan trọng đến vậy. Bộ chia tỷ lệ tự động theo cụm thêm phần cuối cùng bằng cách tự động thêm hoặc xóa các nút khi nhu cầu thay đổi.
Tối ưu hóa GPU có nghĩa là tận dụng từng giọt năng lượng cuối cùng từ mỗi card. Các nhóm điều chỉnh mức sử dụng bộ nhớ, cân bằng tải và đặt mức độ ưu tiên rõ ràng. Những thay đổi đơn giản như phân vùng bộ nhớ tốt hơn hoặc ngăn các thẻ cắt thời gian khỏi bị trống một nửa. Kết quả hiển thị nhanh chóng: công việc đào tạo kết thúc sớm hơn, suy luận diễn ra nhanh hơn và chi phí hàng tháng giảm xuống.
Các mô hình rất lớn không còn vừa với bộ nhớ của một GPU nữa. Mô hình song song khắc phục vấn đề đó. Nó chia mô hình thành các phần nhỏ hơn và gửi từng phần đến một GPU riêng. Tất cả các phần đều được đào tạo cùng lúc nên toàn bộ quá trình sẽ kết thúc nhanh hơn nhiều. Khi tính song song của mô hình hoạt động cùng với tính năng lập lịch GPU thông minh, ngay cả những mô hình lớn nhất cũng sẽ hoạt động trơn tru và sử dụng tài nguyên một cách khôn ngoan.
Trong các tổ chức AI lớn, nhiều nhóm thường yêu cầu tài nguyên GPU cùng một lúc. Nếu không có sự phối hợp phù hợp, một khối lượng công việc có thể chiếm độc quyền một lượng tài nguyên điện toán đáng kể.
Để giải quyết vấn đề này, hiện nay chúng tôi phân bổ các phân vùng GPU dựa trên hạn ngạch người dùng và loại khối lượng công việc. Ví dụ, những công việc đào tạo có nhu cầu cao có thể nhận được truy cập GPU đầy đủ, trong khi khối lượng công việc suy luận hoặc khám phá nhẹ có thể sử dụng Phiên bản MIG hoặc tài nguyên vGPU được chia sẻ.
Mô hình phân bổ nguồn lực này cải thiện đáng kể khả năng sử dụng. Việc phối hợp GPU nhiều người thuê có thể tăng hiệu quả tính toán tổng thể bằng cách 30% đến 40%, trong khi vẫn duy trì sự cô lập và ổn định của khối lượng công việc.
Do đó, các công ty có thể đào tạo đồng thời nhiều mô hình AI, với thời gian thiết lập nhanh hơn và kiểm soát chi phí điện toán tốt hơn.
Ngoài sự cô lập ở cấp độ phần cứng, các framework dựa trên Kubernetes như vLLM và KPhục vụ ngày càng sử dụng cắt MIG để triển khai khối lượng công việc suy luận nhiều bên thuê. Bằng cách tận dụng phân vùng dựa trên MIG, các khung này cung cấp QoS có thể dự đoán được giữa các đối tượng thuê khác nhau đồng thời phù hợp với NUMA mối quan hệ và PAD (Cố vấn vị trí) chiến lược để tối ưu hóa vị trí bộ nhớ và thông lượng.
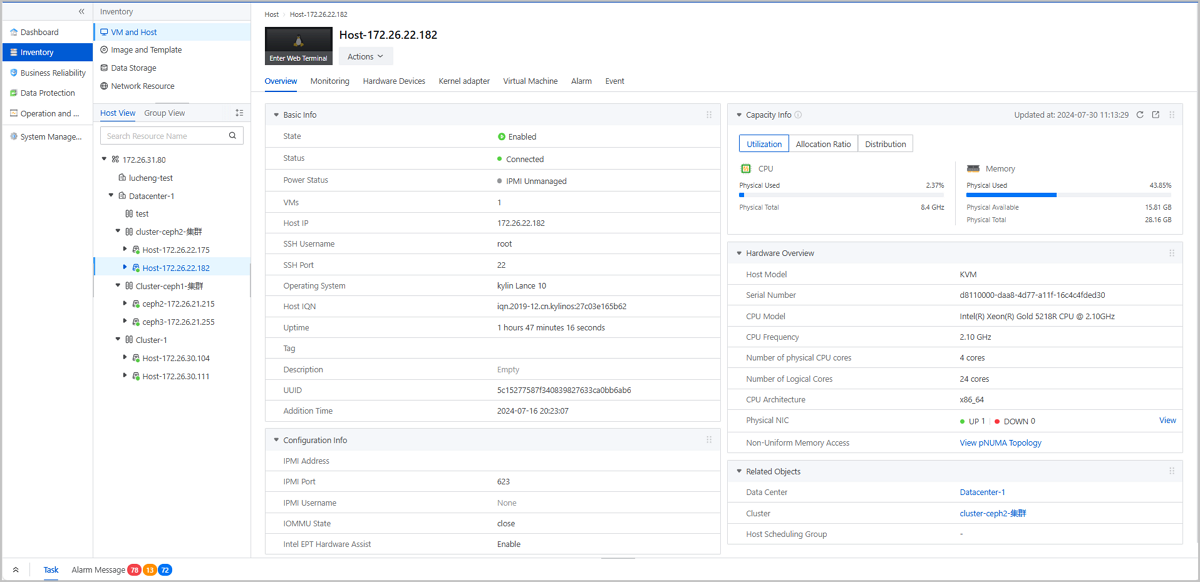
ZStack cung cấp nền tảng đám mây hoàn chỉnh cho phép các công ty kiểm soát hoàn toàn cơ sở hạ tầng AI của riêng họ. Với ZStack Cloud, các nhóm quản lý tài nguyên GPU và lập lịch khối lượng công việc chính xác theo cách họ cần. Hiệu suất vẫn cao nhưng chi phí vẫn có thể dự đoán được. Khi các dự án AI phát triển, nền tảng sẽ mở rộng quy mô mà không buộc các nhóm phải xây dựng lại bất kỳ thứ gì từ đầu.
Nền tảng hàng đầu của công ty, ZStack AIOS, thể hiện một bước tiến lớn trong lĩnh vực cơ sở hạ tầng AI (AI Infra). Nó tích hợp các tài nguyên điện toán, lưu trữ và mạng vào một lớp điều phối thống nhất và được thiết kế đặc biệt cho khối lượng công việc đòi hỏi nhiều GPU. ZStack AIOS đã được giới thiệu trong báo cáo Thông tin đổi mới: Cơ sở hạ tầng AI tại Trung Quốc của Gartner với tư cách là Nhà cung cấp đại diện.
ZStack AIOS giúp việc thiết lập môi trường điện toán đám mây đa GPU trở nên đơn giản. Công việc đào tạo được tự động trải rộng trên nhiều thẻ nên kết quả sẽ quay lại nhanh hơn. Lập kế hoạch GPU tích hợp sẽ theo dõi mọi thẻ và giữ cho khối lượng công việc được cân bằng hoàn hảo. Không có GPU nào bị choáng ngợp. Đồng thời, tính năng chia sẻ GPU cho phép nhiều dự án hoặc người dùng làm việc trên cùng một phần cứng một cách an toàn. Tỷ lệ sử dụng tăng lên và chi phí giảm xuống.
ZStack Cloud tập hợp các công cụ mạnh mẽ để lập lịch khối lượng công việc, tối ưu hóa GPU và song song mô hình ở một nơi. Nó kết nối dễ dàng với các khung AI phổ biến, vì vậy các nhóm tiếp tục sử dụng các công cụ họ đã biết. Bộ chia tỷ lệ tự động theo cụm theo dõi nhu cầu trong thời gian thực và thêm hoặc xóa các nút GPU mà không cần bất kỳ ai nhấp vào nút. Toàn bộ thiết lập vẫn hoạt động hiệu quả ngay cả trong thời gian đào tạo bận rộn nhất.
ZStack sử dụng thuật toán lập lịch GPU thông minh để xem xét nhu cầu của từng công việc và trạng thái cụm hiện tại. Nhiệm vụ sẽ được thực hiện trên thẻ tốt nhất hiện có ngay lập tức. Nút thắt gần như biến mất. Quá trình đào tạo kết thúc trước thời hạn và các nhóm có thể phát triển cũng như triển khai các mô hình mới nhanh hơn trước. Lập kế hoạch khối lượng công việc đảm bảo không có gì phải chờ quá lâu trong hàng đợi.
ZStack đơn giản hóa các hoạt động AI hàng ngày từ đầu đến cuối. Nền tảng của nó xử lý tối ưu hóa GPU, lập lịch khối lượng công việc và chia sẻ GPU mà không cần quá phức tạp. Các công ty xây dựng một nền tảng có thể mở rộng, đáng tin cậy và thân thiện với ngân sách cho tất cả các ứng dụng AI của họ. Cho dù nhóm thực hiện một vài thử nghiệm hay đào tạo các mô hình khổng lồ mỗi tuần,Đám mây ZStack giữ cho mọi thứ hoạt động trơn tru.
Đáp: Lập kế hoạch GPU quyết định cách phân bổ tài nguyên GPU cho các công việc khác nhau. Trong khối lượng công việc AI, việc lập kế hoạch tốt sẽ đảm bảo tất cả các thẻ luôn bận rộn mà không bị chậm trễ. Điều đó trực tiếp cắt giảm thời gian đào tạo mô hình và giữ chi phí thấp hơn.
Trả lời: Với sự trợ giúp của tính năng chia sẻ GPU, một số tác vụ hoặc người dùng có thể chạy trên cùng một thẻ vật lý cùng lúc mà không ảnh hưởng lẫn nhau. Nhìn chung, điều đó làm tăng tỷ lệ sử dụng, giảm nhu cầu về phần cứng bổ sung và khiến việc vận hành toàn bộ cơ sở hạ tầng AI rẻ hơn.
Đáp: Việc lập kế hoạch khối lượng công việc sẽ xem xét nhu cầu của từng công việc và phân công công việc đó cho đúng nguồn lực. Không có gì đứng yên lâu và không có thẻ nào tốn quá nhiều công sức. Kết quả là xử lý nhanh hơn và sử dụng tốt hơn từng đô la chi cho GPU.
Đáp: Tính song song của mô hình chia một mô hình lớn thành nhiều mảnh để nhiều GPU có thể huấn luyện các phần khác nhau cùng một lúc. Cách tiếp cận này rút ngắn đáng kể thời gian đào tạo và cho phép các nhóm làm việc với các mô hình không bao giờ phù hợp trên một thẻ duy nhất.
Trả lời: Bộ chia tỷ lệ tự động theo cụm theo dõi nhu cầu hiện tại và thêm các nút GPU khi công việc chồng chất. Khi mọi thứ lắng xuống, nó sẽ loại bỏ các nút bổ sung. Các công ty chỉ trả tiền cho những gì họ thực sự sử dụng và hiệu suất luôn phù hợp với nhu cầu thực sự.
 2025-02-11
2025-02-11