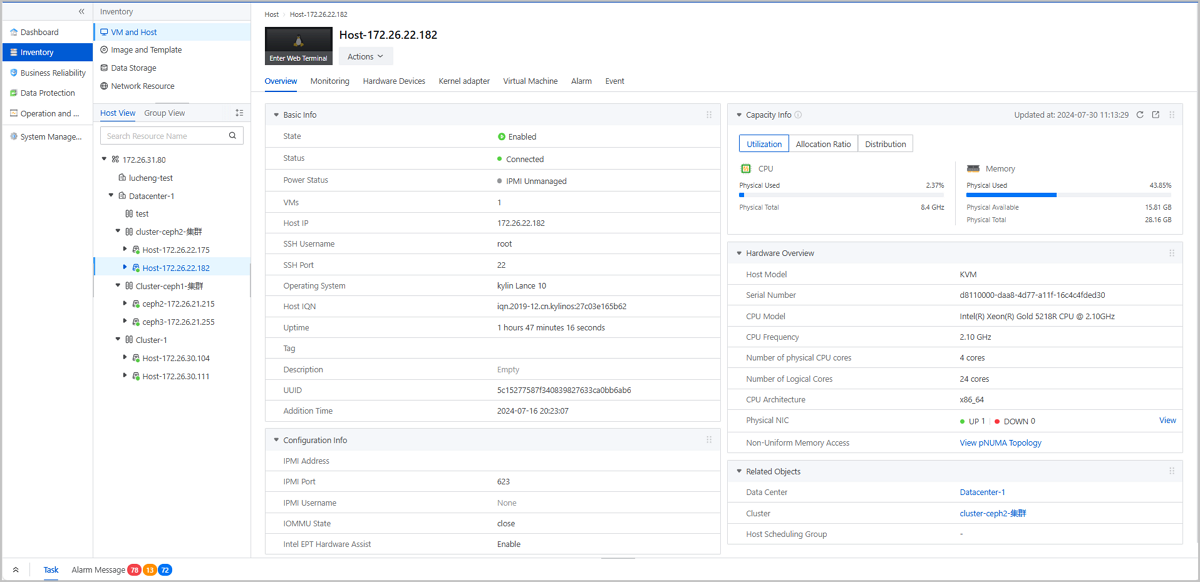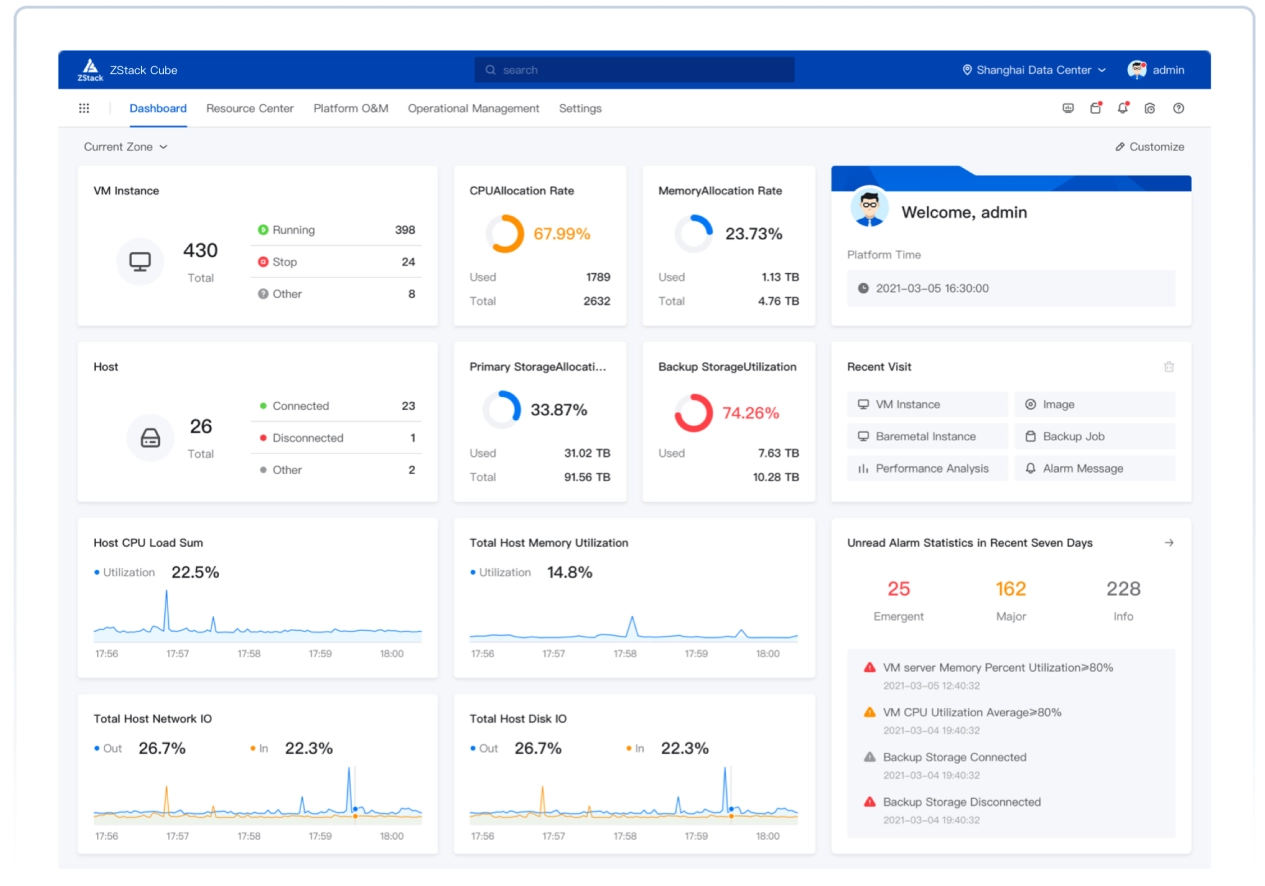
Nền tảng đám mây ZStack
Triển khai một máy chủ với đầy đủ tính năng, miễn phí trong một năm

Tài liệu và công cụ sản phẩm toàn diện

Đề cao giá trị của Khách hàng là trên hết và sứ mệnh Phục vụ Khách hàng, ZStack tận tâm cung cấp các dịch vụ an toàn và ổn định cho khách hàng.

Để giáo dục các đối tác của ZStack và những cá nhân quan tâm về điện toán đám mây và trau dồi tài năng về điện toán đám mây.

ZStack cung cấp cơ sở hạ tầng đám mây sáng tạo cho mười ngành công nghiệp chính

Thông qua ba phần chính, hàng chục ngàn từ và hơn 10 khách hàng đại diện toàn cầu
Trong bài viết Hiểu biết sâu sắc về DeepSeek và thực tiễn doanh nghiệp (Phần 1): Chắt lọc, triển khai và đánh giá, chúng tôi đã khám phá các kỹ thuật chắt lọc và lượng tử hóa của các mô hình sâu, cũng như những kiến thức cơ bản về triển khai của mô hình 7B. Thông thường, bộ nhớ của một GPU có thể xử lý đầy đủ các yêu cầu về thông số của mô hình 7B. Tuy nhiên, khi số lượng tham số tăng lên mức 32B (32 tỷ), bộ nhớ của một GPU thường không thể hỗ trợ hoạt động đầy đủ của nó. Đây là lúc việc suy luận song song đa GPU trở nên cần thiết, bên cạnh việc cân nhắc xem liệu kiến trúc phần cứng của máy chủ có thể hỗ trợ nhiều GPU hay không.
Bài viết này triển khai DeepSeek-Chưng cất-Qwen-32B như một ví dụ. Chúng ta sẽ đi sâu vào các nguyên tắc song song đa GPU và những cân nhắc chính để triển khai nhiều GPU trong một máy chủ. Ngoài ra, chúng tôi sẽ đánh giá hiệu suất thời gian chạy và khả năng suy luận của mô hình 32B, đưa ra phân tích và đề xuất cho các trường hợp sử dụng phù hợp.
Khi triển khai mô hình 32B, các yếu tố như độ chính xác, độ dài ngữ cảnh và kích thước lô ảnh hưởng đáng kể đến nhu cầu bộ nhớ và tính toán. Chúng tôi đã đề cập đến các yếu tố ảnh hưởng cốt lõi trong bài viết trước nên sẽ không nhắc lại chúng ở đây. Thay vào đó, chúng tôi sẽ trực tiếp cung cấp các giá trị được đánh giá:
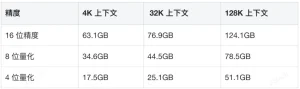
Do sự phức tạp của các phương pháp lượng tử hóa hiện đại (ví dụ: đóng gói dữ liệu, lượng tử hóa định dạng FP8, v.v.), việc gắn nhãn chúng là Int8 hoặc Int4 sẽ kém chính xác hơn. Vì vậy, chúng tôi sẽ sử dụng Lượng tử hóa 8 bit và Lượng tử hóa 4 bit để ước tính ở đây.
Các biến thể bổ sung có thể phát sinh do chiến lược lượng tử hóa cho các lớp khác nhau, độ chính xác của cấu trúc dữ liệu, liệu lượng tử hóa bộ đệm KV có được bật hay không hoặc việc sử dụng các khung suy luận khác nhau.

Từ các tính toán ở trên, rõ ràng là với bối cảnh lớn—đặc biệt là ở độ chính xác dữ liệu cao hơn—một GPU sẽ gặp khó khăn trong việc đáp ứng nhu cầu bộ nhớ. GPU dành cho người tiêu dùng thông thường thường cung cấp bộ nhớ lên tới 24GB, trong khi thẻ tập trung vào suy luận đạt tới 48GB. Chỉ một số GPU cao cấp cung cấp 64–141GB.
Như vậy, đối với những dòng máy có thông số từ 32B trở lên thì việc suy luận đa GPU là điều gần như khó tránh khỏi. Các chiến lược song song đa GPU chính hiện nay là Song song Tensor và Song song đường ống.
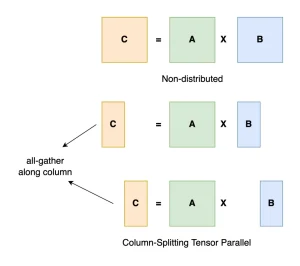
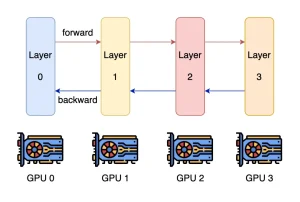
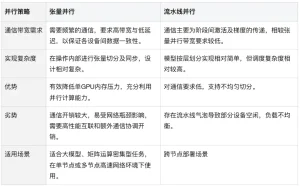
Từ bảng trên, Tính song song của Tensor vượt trội trong việc tăng thông lượng tổng thể. Tuy nhiên, Pipeline Parallelism dễ triển khai hơn và phù hợp với các kịch bản suy luận hỗn hợp CPU-GPU. Đây là lý do tại sao llama.cpp (công cụ suy luận được sử dụng bởi ollama) chọn Song song đường ống. Nó cũng giải thích tại sao hiệu suất đa GPU của llama.cpp tương đối yếu hơn.
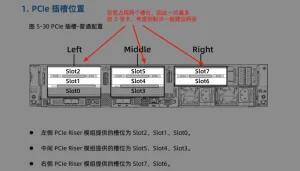
Hầu hết các GPU đều có chiều rộng gấp đôi, chiếm hai khe cắm PCIe. Ngay cả khi không có các thiết bị khác sử dụng khe cắm, máy chủ 2U thông thường chỉ có thể chứa được ba GPU. Vì điều này không phù hợp với lũy thừa 2 nên chỉ có thể sử dụng tối đa hai GPU.
Giảm số lượng ổ đĩa mặt trước: Giải phóng không gian và cải thiện khả năng làm mát bằng cách sử dụng ổ đĩa có dung lượng lớn hơn thay vì nhiều ổ đĩa nhỏ hơn.
Sử dụng mô-đun đa GPU: Một số nhà cung cấp máy chủ cung cấp các mô-đun GPU chuyên dụng. Chúng dành toàn bộ không gian 1U phía trên cho GPU, cho phép tối đa 4 GPU có chiều rộng gấp đôi cạnh nhau.

Tại thời điểm này, bảng điều khiển phía trước phải dự trữ luồng không khí để làm mát. Như vậy, nó chỉ có thể chứa được 8 ổ đĩa 3,5 inch. Cần có ổ đĩa dung lượng lớn hơn để đảm bảo đủ dung lượng lưu trữ.
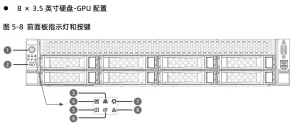
Để có nhiều ổ đĩa hơn hoặc làm mát tốt hơn, cần có máy chủ 3U, 4U hoặc cao hơn. Thiết lập tối ưu phụ thuộc vào nguồn điện của tủ và mức tiêu thụ điện năng của GPU.
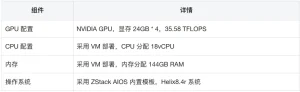
Các bước triển khai
Đánh giá hiệu suất
Sử dụng thử nghiệm hiệu suất của ZStack AIOS Helix, chúng tôi đã nhanh chóng đánh giá hiệu suất của mô hình trên phần cứng hiện tại. Dữ liệu được tóm tắt như sau:
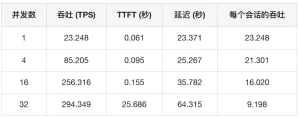
Kết hợp những kết quả này, chúng ta có thể phân tích môi trường hiện tại:
Thông lượng (TPS) so với đồng thời
Những phát hiện chính về độ trễ phản hồi
Phân tích hiệu quả tài nguyên
Cấu hình được đề xuất cho các tình huống khác nhau
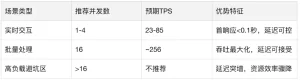
Với các công cụ đánh giá của ZStack AIOS Helix và điều kiện thực tế, việc tìm kiếm kế hoạch kinh doanh và mô hình triển khai phù hợp trở nên dễ dàng hơn.
Lưu ý: Các thử nghiệm cho thấy 16 lần đồng thời là mức cân bằng thông lượng/độ trễ tối ưu. Ngoài ra, hiệu suất giảm đáng kể. Xác thực bằng các bài kiểm tra căng thẳng dựa trên tài nguyên phần cứng trong quá trình triển khai thực tế.
2. Kết quả đánh giá
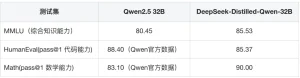
Mô hình 32B vượt trội ở nhiều lĩnh vực:
Vì vậy, chúng tôi đã xác định được các trường hợp sử dụng tiềm năng cho tìm kiếm sâu-Chưng-Qwen-32B:
Thông qua việc khám phá này, chúng tôi đã có được những hiểu biết sâu sắc về việc triển khai đa GPU của DeepSeek-Chưng cất-Qwen-32B, yêu cầu phần cứng và hiệu suất trên các chiến lược chính xác và song song. Khả năng mạnh mẽ của mô hình 32B mở ra những khả năng mới cho các ứng dụng doanh nghiệp. Nhìn về phía trước, chúng tôi dự đoán sẽ thấy được giá trị và tiềm năng của nó trong nhiều tình huống thực tế hơn.
Trong các bài viết tiếp theo, chúng tôi sẽ đề cập đến:
Bằng cách so sánh các mô hình có kích thước và độ chính xác khác nhau, chúng tôi mong muốn cung cấp các kế hoạch triển khai chi tiết, toàn diện để doanh nghiệp sử dụng. Điều này sẽ giúp các ngành áp dụng công nghệ mô hình ngôn ngữ lớn một cách nhanh chóng, mở ra giá trị kinh doanh.
Lưu ý: Một số dữ liệu trong bài viết này mang tính minh họa. Điều kiện thực tế có thể khác nhau. Việc kiểm tra và xác nhận chi tiết được khuyến nghị trong quá trình thực hiện.
 2025-02-11
2024-12-12
2025-02-11
2024-12-12