Nền tảng đám mây ZStack
Triển khai một máy chủ với đầy đủ tính năng, miễn phí trong một năm

Tài liệu và công cụ sản phẩm toàn diện

Đề cao giá trị của Khách hàng là trên hết và sứ mệnh Phục vụ Khách hàng, ZStack tận tâm cung cấp các dịch vụ an toàn và ổn định cho khách hàng.

Để giáo dục các đối tác của ZStack và những cá nhân quan tâm về điện toán đám mây và trau dồi tài năng về điện toán đám mây.

ZStack cung cấp cơ sở hạ tầng đám mây sáng tạo cho mười ngành công nghiệp chính

Thông qua ba phần chính, hàng chục ngàn từ và hơn 10 khách hàng đại diện toàn cầu
Trong các bài viết trước của loạt bài này trong vài ngày qua, chúng tôi đã khám phá sâu sắc tìm kiếm sâukỹ thuật chưng cất, chiến lược lượng tử hóa cũng như các yếu tố cần thiết khi triển khai và đánh giá hiệu suất của các mô hình lượng tử hóa 7B, 32B và 671B. Điều này đã giúp người đọc lựa chọn giải pháp triển khai mô hình phù hợp với những hạn chế về nguồn lực khác nhau.
Khi các doanh nghiệp tăng cường khám phá các ứng dụng AI, mô hình toàn năng 671B của dòng DeepSeek, với khả năng suy luận đặc biệt cho các tác vụ cực kỳ phức tạp, đã trở thành tài sản quan trọng để tăng cường khả năng cạnh tranh. Tuy nhiên, kích thước tham số lớn của nó có nghĩa là việc triển khai GPU đơn hoặc máy đơn không thể phát huy hết tiềm năng của nó. Việc triển khai nhiều máy, nhiều GPU kết hợp với nền tảng ZStack AIOS là rất quan trọng để khai thác các khả năng của nó. Bài viết này sẽ trình bày chi tiết quy trình thực tế triển khai mô hình toàn năng 671B trên nền tảng AIOS bằng cách sử dụng nhiều máy và GPU, phân tích hiệu suất của nó, đồng thời cung cấp hỗ trợ và hướng dẫn mạnh mẽ cho các doanh nghiệp áp dụng công nghệ AI.
Đối với các model lớn hiện nay, quy trình vận hành GPU có thể được đơn giản hóa thành các bước sau:
Trong quá trình này, hai thông số phần cứng GPU là quan trọng nhất:
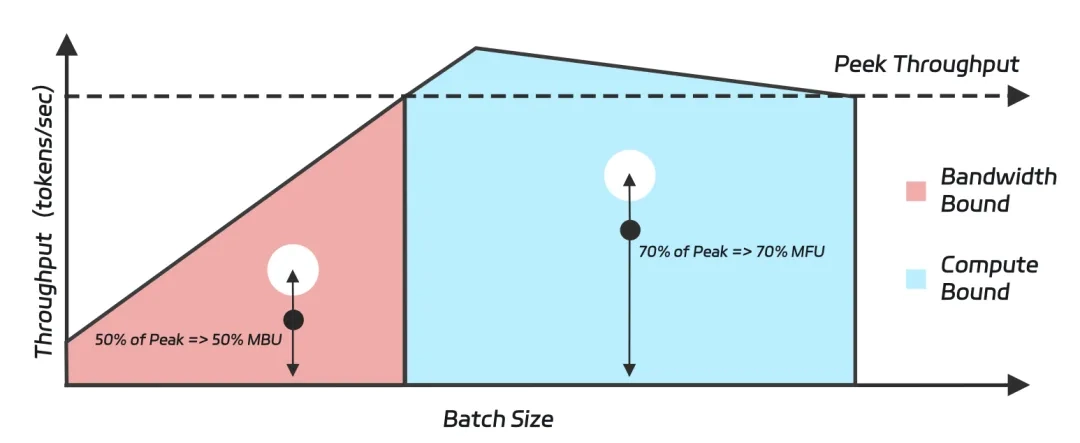
Đối với các GPU hiện đại, “hiệu ứng thắt cổ chai” của cái sau thường lớn hơn cái trước. Dưới đây là so sánh về sức mạnh tính toán và băng thông bộ nhớ của một số GPU phổ biến:
Lấy RTX 4090 làm ví dụ: với FP8, nó có thể xử lý 82TB dữ liệu mỗi giây, nhưng băng thông bộ nhớ của nó chỉ cho phép tải 1TB mỗi giây. Do đó, trong suy luận mô hình lớn, khi tính đồng thời thấp, băng thông bộ nhớ thường là nút thắt cổ chai. Chỉ khi khả năng tương tranh đủ cao thì nút cổ chai mới chuyển từ “bộ nhớ” sang “sức mạnh tính toán”. Điều này giải thích tại sao nhiều thử nghiệm mô hình 671B cho thấy thông lượng tăng lên với khả năng xử lý đồng thời cao hơn.
Ước tính hiệu suất lý thuyết cho Mô hình 671B
Đối với DeepSeek V3 và R1, tổng số tham số là 671B. Nhờ kiến trúc MoE (Hỗn hợp các chuyên gia), chỉ có 37B tham số được kích hoạt trong thời gian chạy. Với biểu diễn FP8 (1 byte cho mỗi tham số), dữ liệu được đọc trên mỗi mã thông báo là:
37B × 1 byte = 37 GB
Lưu ý: Đối với biểu diễn FP16, con số này tăng gấp đôi lên 74 GB/mã thông báo.
Giả sử băng thông bộ nhớ GPU xấp xỉ 1979 GB/s, không phân chia song song trên một GPU, thời gian tính toán trên mỗi byte là:
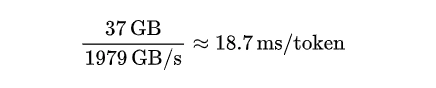
Điều này tương ứng với thông lượng khoảng 53,5 token/s.
Lưu ý: Tính toán này thể hiện giới hạn dưới về mặt lý thuyết trong các điều kiện “cực đoan”. Trong thực tế, các yếu tố như tính toán chồng chéo, số lần truy cập bộ đệm, số lần đọc bộ đệm KV (tăng theo độ dài chuỗi) và các kỹ thuật tối ưu hóa hoặc điều kiện hiển thị khác nhau có thể làm thay đổi kết quả.
Mặc dù ước tính này là sơ bộ và không tính đến việc tối ưu hóa song song tensor (trong đó mỗi GPU tải ít tham số được kích hoạt hơn), chi phí liên lạc và đồng bộ hóa từ song song tensor, cùng với việc giảm mức sử dụng băng thông bộ nhớ, phù hợp chặt chẽ với các thử nghiệm suy luận một người dùng thực tế của chúng tôi cho DeepSeek. Nếu không tối ưu hóa tích cực, hiệu suất suy luận của một người dùng hiếm khi vượt quá 53,5 mã thông báo/giây.
Đối với suy luận mô hình lớn, chiến lược tối ưu hóa được chia thành ba loại:
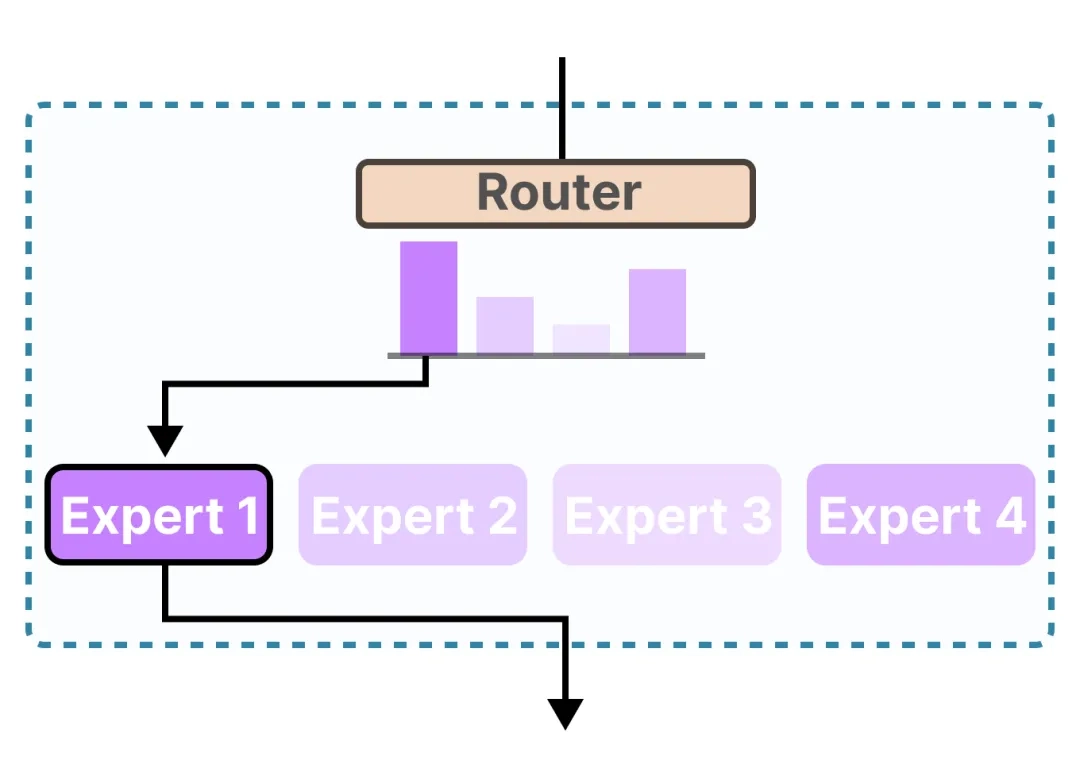

Cân bằng chi phí và hiệu suất
Sơ đồ triển khai trong bài viết DeepSeek-V3 (sử dụng 352 GPU H800 trên mỗi đơn vị trên cụm H800) tận dụng tính song song cao để tối đa hóa hiệu suất GPU, đạt được thông lượng rất cao nhưng với chi phí cao. Để đạt được thông lượng cao với chi phí thấp hơn, trước tiên chúng tôi đã thử nghiệm hiệu năng với ít GPU hơn:
Thiết lập môi trường
Kết quả thực hiện
Không có giải mã suy đoán:
Chúng tôi cũng đã thử nghiệm việc kích hoạt giải mã suy đoán MTP với các tối ưu hóa bổ sung
Những quan sát chính sau khi bật giải mã suy đoán MTP và các tối ưu hóa khác:
Nhìn chung, giải mã suy đoán MTP duy trì thông lượng tốt trong khi cung cấp thời gian phản hồi mã thông báo đầu tiên tốt trong hầu hết các trường hợp. Tuy nhiên, ở mức đồng thời rất cao, thời gian phản hồi sẽ tăng do chi phí tính toán của việc giải mã suy đoán, điều này có thể bù đắp lợi ích của nó trong cài đặt song song quy mô lớn.
Vì khó có được GPU H200 hơn nên chúng tôi đã thử nghiệm với hai thiết lập H20 96GB * 8. Sau khi định cấu hình các điều kiện mạng, chúng tôi quan sát thấy hiệu suất với TP=16 trên các độ trễ mạng và đồng thời khác nhau.
Lưu ý: TP đề cập đến tính song song của Tensor.
Sơ đồ cấu trúc liên kết phần cứng nội bộ của Môi trường SetupServer:
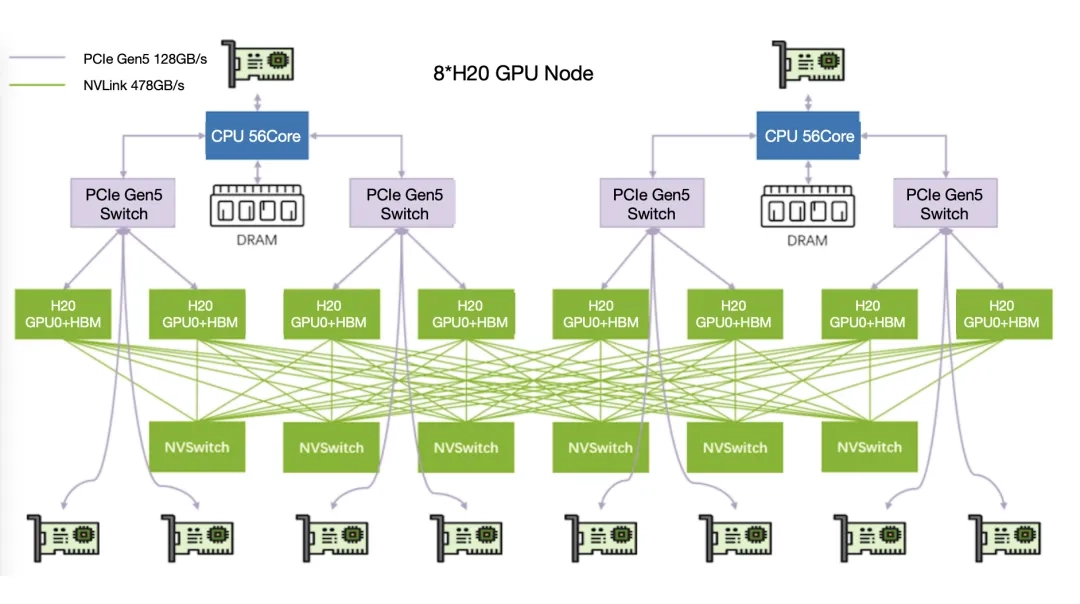
Kết quả triển khai trên Nền tảng ZStack AIOS:
Tiếp theo, chúng tôi đã kiểm tra hiệu suất bằng công cụ đánh giá dịch vụ của ZStack AIOS:
Kết quả thực hiện TP16
Để đánh giá tác động của độ trễ mạng đối với sơ đồ triển khai TP16, chúng tôi đã giới thiệu độ trễ một cách giả tạo bằng cách sử dụng tc và so sánh thông lượng (TPS) trong các độ trễ mạng khác nhau:
Tóm tắt trong biểu đồ:
Những phát hiện chính:
Từ bảng và biểu đồ, khi độ trễ mạng tăng từ 0,193 mili giây lên 2,193 mili giây, thông lượng của TP16 giảm từ 18,943 mã thông báo/giây xuống 4,85 mã thông báo/giây—hiệu suất giảm tối đa là 74%. Điều này cho thấy độ trễ mạng tăng lên làm giảm đáng kể thông lượng TP16.
Vì đây là thử nghiệm đồng thời đơn lẻ nên tác động của độ trễ mạng đến thông lượng TP16 là rất rõ ràng. Do đó, khi thiết kế và triển khai các giải pháp TP16, việc giảm thiểu độ trễ mạng là rất quan trọng để tối ưu hóa thông lượng và hiệu suất.
Mặc dù các phương pháp trên đã cải thiện đáng kể hiệu quả suy luận, nhưng các chiến lược tối ưu hóa tích cực hơn trong môi trường cụm quy mô lớn có thể có khả năng nhân hiệu suất hơn nữa:
Thông qua các thử nghiệm và phân tích lý thuyết ở trên, chúng tôi đã xác thực các điểm nghẽn về hiệu suất của mô hình lớn ở các mức độ đồng thời khác nhau. Bằng cách tận dụng các lợi thế kiến trúc MLA và MoE độc đáo của DeepSeek, kết hợp với lượng tử hóa FP8 và mô-đun MTP, hiệu suất phần cứng GPU có thể được tận dụng tối đa. Về phía mạng, các chiến lược song song linh hoạt có thể được cấu hình dựa trên điều kiện mạng để tối ưu hóa thông lượng hệ thống.
Trong tương lai, các chiến lược như song song chuyên gia, song song dữ liệu, chuyên gia dự phòng, tối ưu hóa truyền thông và chồng chéo nhiều vi chương trình có thể nâng cao hơn nữa hiệu suất hệ thống, cung cấp nền tảng kỹ thuật vững chắc cho việc triển khai trên quy mô lớn.
Điều này kết thúc một phân tích toàn diện và triển vọng triển khai doanh nghiệp dựa trên lý thuyết hiện tại và thực tiễn triển khai mô hình DeepSeek. Chúng tôi hy vọng bài viết này cung cấp tài liệu tham khảo và nguồn cảm hứng cho các kỹ sư và người ra quyết định của doanh nghiệp trong việc triển khai mô hình lớn.
Trong lĩnh vực AI, việc lặp lại mô hình phát triển nhanh chóng và mô hình đột phá tiếp theo có thể xuất hiện bất cứ lúc nào. Vì vậy, doanh nghiệp phải thiết lập cơ chế lựa chọn và đánh giá mô hình dài hạn để đón đầu các xu hướng công nghệ. Khi lựa chọn mô hình AI, doanh nghiệp nên chọn các mô hình có kích thước tham số và sơ đồ triển khai phần cứng phù hợp dựa trên nhu cầu kinh doanh thực tế, tạo ra sự cân bằng tối ưu giữa hiệu suất suy luận và chi phí.
Trong các bài viết tiếp theo, chúng ta sẽ khám phá:
Hãy theo dõi các ZStack tài khoản công cộng! Chúng tôi sẽ tiếp tục tối ưu hóa và tập trung vào các giải pháp hiệu quả về chi phí và hiệu suất suy luận của mô hình DeepSeek, đồng thời đưa ra các chiến lược triển khai toàn diện và chi tiết cho các ứng dụng doanh nghiệp. Điều này sẽ giúp nhiều ngành nhanh chóng áp dụng công nghệ mô hình ngôn ngữ lớn và hiện thực hóa giá trị kinh doanh.
 2025-02-11
2025-02-11