Nền tảng đám mây ZStack
Triển khai một máy chủ với đầy đủ tính năng, miễn phí trong một năm

Tài liệu và công cụ sản phẩm toàn diện

Đề cao giá trị của Khách hàng là trên hết và sứ mệnh Phục vụ Khách hàng, ZStack tận tâm cung cấp các dịch vụ an toàn và ổn định cho khách hàng.

Để giáo dục các đối tác của ZStack và những cá nhân quan tâm về điện toán đám mây và trau dồi tài năng về điện toán đám mây.

ZStack cung cấp cơ sở hạ tầng đám mây sáng tạo cho mười ngành công nghiệp chính

Thông qua ba phần chính, hàng chục ngàn từ và hơn 10 khách hàng đại diện toàn cầu
Do giá thành GPU cao, đặc biệt là GPU cao cấp, các công ty thường có suy nghĩ: Hiệu suất sử dụng GPU hiếm khi đạt 100% mọi lúc. Liệu chúng ta có thể chia GPU ra, tương tự như chạy nhiều máy ảo trên một máy chủ, phân bổ một phần cho mỗi người dùng để cải thiện đáng kể việc sử dụng GPU?
Tuy nhiên, trên thực tế, GPU ảo hóa tụt hậu xa so với ảo hóa CPU vì một số lý do:
1. Sự khác biệt cố hữu trong cách hoạt động của GPU và CPU
2. Sự khác biệt cố hữu trong trường hợp sử dụng GPU và CPU
3. Sự khác biệt trong quá trình phát triển của nhà sản xuất và ngành
Hôm nay, chúng ta sẽ bắt đầu với phần tổng quan về cách hoạt động của GPU và khám phá một số phương pháp chia sẻ tài nguyên GPU, cuối cùng là thảo luận về loại chia sẻ GPU mà hầu hết các doanh nghiệp cần trong kỷ nguyên AI cũng như cách cải thiện hiệu quả và việc sử dụng GPU.
1. Kiến trúc phần cứng song song cao
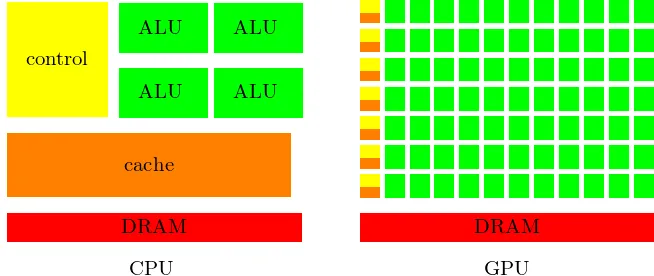
GPU (Bộ xử lý đồ họa) ban đầu được thiết kế để tăng tốc đồ họa và là bộ xử lý được xây dựng để tính toán song song dữ liệu quy mô lớn. So với bản chất mục đích chung của CPU, GPU chứa một số lượng lớn bộ xử lý đa luồng (SM hoặc các thuật ngữ tương tự), có khả năng thực thi đồng thời hàng trăm hoặc thậm chí hàng nghìn luồng theo một Lệnh đơn, Nhiều dữ liệu (SIMD hoặc gần như SIMT).
2. Bộ nhớ bối cảnh và video (VRAM)
Bối cảnh: Trong môi trường lập trình CUDA, nếu các quy trình (hoặc vùng chứa) khác nhau muốn sử dụng GPU thì mỗi quy trình cần có Ngữ cảnh CUDA riêng. GPU chuyển đổi giữa các bối cảnh này thông qua việc cắt thời gian hoặc hợp nhất chúng để chia sẻ (ví dụ: NVIDIA MPS hợp nhất nhiều quy trình thành một bối cảnh duy nhất).
Bộ nhớ video (VRAM): Dung lượng bộ nhớ trong của GPU thường cố định và khả năng quản lý của nó khác với CPU (chủ yếu sử dụng MMU của nhân hệ điều hành để phân trang bộ nhớ). GPU thường yêu cầu phân bổ VRAM rõ ràng. Như được hiển thị trong sơ đồ bên dưới, GPU có nhiều ALU, mỗi ALU có không gian bộ đệm riêng:
3. Chế độ lập lịch và phần cứng phía GPU
Chuyển đổi bối cảnh GPU phức tạp hơn và kém hiệu quả hơn đáng kể so với chuyển đổi CPU. GPU thường cần hoàn tất việc chạy kernel (chức năng tính toán phía GPU) trước khi chuyển đổi và việc lưu/khôi phục dữ liệu ngữ cảnh giữa các tiến trình sẽ phát sinh chi phí cao hơn so với chuyển đổi ngữ cảnh của CPU.
Tài nguyên GPU có hai chiều chính: sức mạnh tính toán (tương ứng với SM, v.v.) và VRAM. Trong thực tế, phải xem xét cả việc sử dụng điện toán và tính khả dụng của VRAM.
1. Ảo hóa CPU hoàn thiện với bộ hướng dẫn mạnh mẽ và hỗ trợ phần cứng
Ảo hóa CPU (ví dụ: KVM, Xen, VMware) đã được phát triển trong nhiều thập kỷ, với sự hỗ trợ phần cứng mở rộng (ví dụ: Intel VT-x, AMD-V). Bối cảnh CPU tương đối đơn giản và các nhà cung cấp phần cứng đã hợp tác chặt chẽ với các nhà cung cấp ảo hóa.
2. Tính song song cao và chuyển đổi ngữ cảnh tốn kém trong GPU
Do sự phức tạp và chi phí chuyển đổi bối cảnh GPU cao so với CPU, nên việc “chia sẻ” trên GPU đòi hỏi phải xử lý linh hoạt quyền truy cập đồng thời của các quy trình khác nhau, tranh chấp VRAM và khả năng tương thích với trình điều khiển hạt nhân nguồn đóng. Đối với GPU có hàng trăm hoặc hàng nghìn lõi, các nhà sản xuất gặp khó khăn trong việc cung cấp khả năng trừu tượng hóa phần cứng đầy đủ ở cấp độ tập lệnh như CPU thực hiện hoặc yêu cầu một quá trình phát triển kéo dài.
(Sơ đồ bên dưới minh họa việc chuyển đổi ngữ cảnh GPU, cho thấy độ trễ đáng kể mà nó gây ra.)
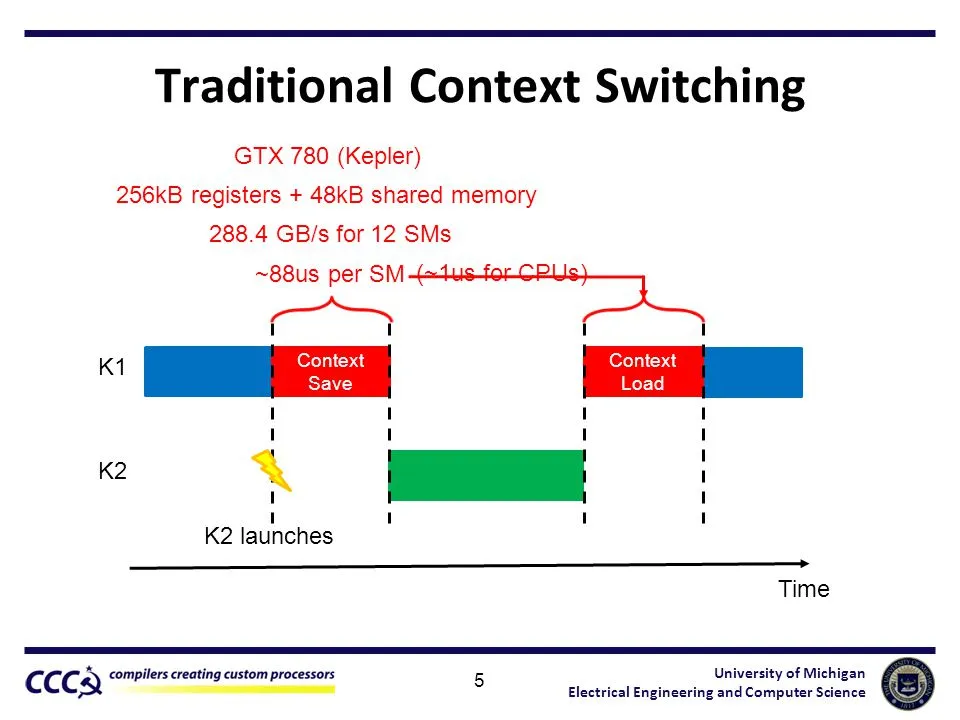
3. Sự khác biệt về nhu cầu ca sử dụng
CPU thường được chia sẻ trên các máy ảo hoặc bộ chứa nhiều người dùng quy mô lớn, với hầu hết các trường hợp sử dụng đòi hỏi hiệu suất CPU cao nhưng không phải là các hoạt động nhân hoặc tích chập ma trận hàng nghìn luồng dữ liệu thường thấy trong đào tạo học sâu. Trong các kịch bản suy luận và đào tạo GPU, mục tiêu thường là tối đa hóa sức mạnh tính toán cao nhất. Ảo hóa hoặc chia sẻ gây ra chi phí chuyển đổi ngữ cảnh và xung đột với đảm bảo QoS tài nguyên, dẫn đến phân mảnh kỹ thuật.
4. Các biến thể của hệ sinh thái nhà cung cấp
Các nhà cung cấp CPU tương đối hợp nhất, trong đó Intel và AMD thống trị ở nước ngoài với kiến trúc x86, trong khi các nhà cung cấp trong nước chủ yếu sử dụng x86 (hoặc C86), ARM và đôi khi là các bộ hướng dẫn độc quyền như LoongArch. Ngược lại, các nhà cung cấp GPU thể hiện sự đa dạng đáng kể, chia thành các nhóm như CUDA, tương thích CUDA, ROCm và các hệ sinh thái độc quyền khác nhau bao gồm CANN, dẫn đến một hệ sinh thái bị phân mảnh nặng nề.
Tóm lại, những yếu tố này khiến công nghệ chia sẻ GPU tụt hậu so với sự trưởng thành và linh hoạt của ảo hóa CPU.
Nói rộng hơn, các phương pháp chia sẻ GPU có thể được phân loại thành các loại sau (tên có thể khác nhau, nhưng nguyên tắc thì tương tự nhau):
1. vGPU (các cách triển khai khác nhau ở cấp độ phần cứng/nhân/người dùng, ví dụ: NVIDIA vGPU, AMD MxGPU, cGPU/qGPU cấp nhân)
2. MPS (Dịch vụ đa tiến trình NVIDIA, giải pháp hợp nhất ngữ cảnh)
3. MIG (GPU đa phiên bản NVIDIA, cách ly phần cứng trong kiến trúc A100/H100)
4. Móc CUDA (Chiếm quyền điều khiển/chặn chặn API, ví dụ: các giải pháp cấp người dùng như GaiaGPU)
Nguyên tắc cơ bản: Chia một GPU thành nhiều phiên bản GPU ảo (vGPU) thông qua cơ chế cấp nhân hoặc cấp người dùng. NVIDIA vGPU và AMD MxGPU là những giải pháp phần cứng/phần mềm chính thức được hỗ trợ mạnh mẽ nhất. Các tùy chọn nguồn mở như KVMGT (Intel GVT-g), cGPU và qGPU cũng tồn tại.
Ưu điểm:
Phân bổ linh hoạt sức mạnh tính toán và VRAM, cho phép “chạy nhiều vùng chứa hoặc VM trên một thẻ”.
Hỗ trợ hoàn thiện từ các nhà cung cấp phần cứng (ví dụ: NVIDIA vGPU, AMD MxGPU) với QoS mạnh mẽ, bảo trì trình điều khiển và khả năng tương thích hệ sinh thái.
Nhược điểm:
Một số giải pháp chính thức (ví dụ: NVIDIA vGPU) chỉ hỗ trợ máy ảo chứ không hỗ trợ bộ chứa và có chi phí cấp phép cao.
Các giải pháp cấp độ hạt nhân/người dùng nguồn mở (ví dụ: vCUDA, cGPU) có thể yêu cầu thích ứng với các phiên bản CUDA khác nhau và cung cấp khả năng bảo mật/cách ly yếu hơn so với các giải pháp phần cứng chính thức.
Trường hợp sử dụng:
Các doanh nghiệp cần máy tính để bàn, máy trạm ảo được tăng tốc GPU hoặc kết xuất trò chơi trên đám mây.
Sự cùng tồn tại của nhiều dịch vụ yêu cầu hạn ngạch VRAM/điện toán với nhu cầu sử dụng cao.
Cần mức độ cách ly bảo mật vừa phải nhưng có thể chịu được chi phí thích ứng và cấp phép.
(Sơ đồ bên dưới thể hiện nguyên tắc vGPU, trong đó một GPU vật lý được chia thành ba vGPU được chuyển đến các máy ảo.)
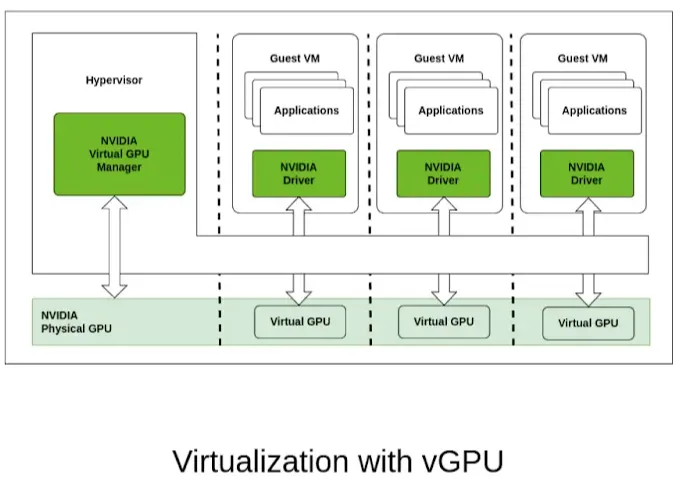
Nguyên tắc cơ bản: Phương pháp chia sẻ “hợp nhất ngữ cảnh” do NVIDIA cung cấp cho các kiến trúc Volta và các kiến trúc mới hơn. Nhiều quy trình hoạt động như Máy khách MPS, hợp nhất các yêu cầu điện toán của chúng vào một ngữ cảnh MPS Daemon duy nhất, sau đó sẽ đưa ra lệnh cho GPU.
Ưu điểm:
Hiệu suất tốt hơn: Các hạt nhân từ các quy trình khác nhau có thể xen kẽ ở cấp độ vi mô (được lên lịch song song bởi phần cứng GPU), giảm việc chuyển đổi ngữ cảnh thường xuyên; lý tưởng cho nhiều nhiệm vụ suy luận nhỏ hoặc đào tạo nhiều quy trình trong cùng một khuôn khổ.
Sử dụng trình điều khiển chính thức có khả năng tương thích phiên bản CUDA tốt, giảm thiểu sự thích ứng của bên thứ ba.
Nhược điểm:
Cách ly lỗi kém: Nếu MPS Daemon hoặc một tác vụ bị lỗi, tất cả các quy trình được chia sẻ đều bị ảnh hưởng.
Không cách ly VRAM cứng; cần lập kế hoạch ở cấp độ cao hơn để ngăn chặn rò rỉ bộ nhớ của một quy trình ảnh hưởng đến các quy trình khác.
Trường hợp sử dụng:
Các kịch bản “suy luận quy mô nhỏ” điển hình để tối đa hóa thông lượng song song.
Đóng gói nhiều công việc nhỏ vào một GPU (yêu cầu cách ly lỗi cẩn thận và quản lý tranh chấp VRAM).
(Sơ đồ bên dưới minh họa MPS, hiển thị các tác vụ từ hai quy trình được hợp nhất thành một ngữ cảnh, chạy gần như song song trên GPU.)
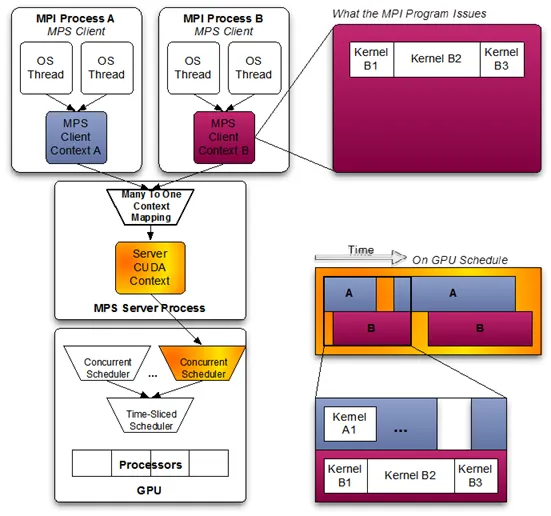
Nguyên tắc cơ bản: Một giải pháp cách ly cấp phần cứng được NVIDIA giới thiệu trong các kiến trúc Ampere (A100, H100) và các kiến trúc mới hơn. Nó phân vùng trực tiếp SM, bộ đệm L2 và bộ điều khiển VRAM, cho phép chia A100 thành tối đa bảy thẻ phụ, mỗi thẻ có sự cách ly phần cứng mạnh mẽ.
Ưu điểm:
Cách ly cao nhất: VRAM, băng thông, v.v. được phân chia ở cấp độ phần cứng, không có sự lan truyền lỗi giữa các phiên bản.
Không yêu cầu móc hoặc giấy phép API bên ngoài (dựa trên các tính năng phần cứng A100/H100).
Nhược điểm:
Tính linh hoạt hạn chế: Chỉ hỗ trợ một số phiên bản GPU cố định (ví dụ: 1g.5gb, 2g.10gb, 3g.20gb), thường là bảy phiên bản trở xuống, với độ chi tiết thô.
Không được hỗ trợ trên GPU cũ hơn A100/H100 (hoặc A30, A16); GPU cũ không thể được hưởng lợi.
Trường hợp sử dụng:
Điện toán hiệu năng cao, công cộng/riêng tưđám mây yêu cầu sự song song của nhiều bên thuê với sự cách ly nghiêm ngặt và phân bổ tĩnh.
Nhiều người dùng chia sẻ một máy chủ GPU lớn, mỗi người dùng chỉ cần một phần sức mạnh tính toán của A100 mà không bị nhiễu.
(Sơ đồ bên dưới hiển thị các cấu hình được hỗ trợ cho A100 MIG.)
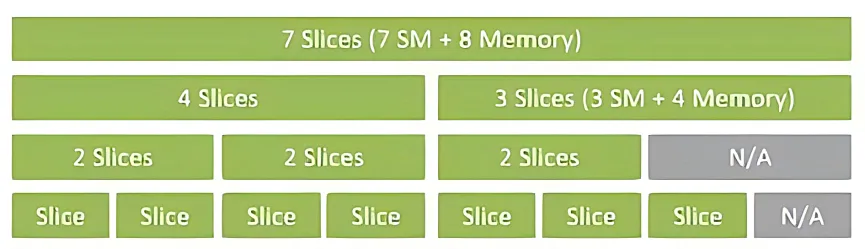
Nguyên tắc cơ bản: Sửa đổi hoặc chặn các thư viện động CUDA (API thời gian chạy hoặc API trình điều khiển) để ghi lại các lệnh gọi ứng dụng tới GPU (ví dụ: phân bổ VRAM, gửi kernel), sau đó áp dụng các giới hạn tài nguyên, lập lịch và thống kê trong không gian người dùng hoặc quy trình phụ trợ.
Ưu điểm:
Rào cản phát triển thấp hơn: Không cần thay đổi lớn về kernel hoặc cần hỗ trợ phần cứng mạnh; khả năng tương thích tốt hơn với GPU hiện có.
Cho phép điều chỉnh/hạn ngạch linh hoạt (ví dụ: lập lịch hợp nhất, số liệu thống kê sử dụng GPU, thực thi hạt nhân bị trì hoãn).
Nhược điểm:
Cách ly lỗi/chi phí hiệu năng: Tất cả các cuộc gọi đều đi qua hook để phân tích và lập lịch, yêu cầu xử lý cẩn thận việc chuyển ngữ cảnh đa quy trình.
Trong đào tạo quy mô lớn, việc chiếm quyền điều khiển/thiết bị thường xuyên sẽ gây ra tình trạng giảm hiệu suất.
Trường hợp sử dụng:
Doanh nghiệp nội bộ hoặc nhu cầu nhiệm vụ cụ thể đòi hỏi phải “cắt lát” nhanh GPU lớn.
Các tình huống phát triển trong đó một thẻ tạm thời được chia cho nhiều công việc nhỏ để tăng mức sử dụng.
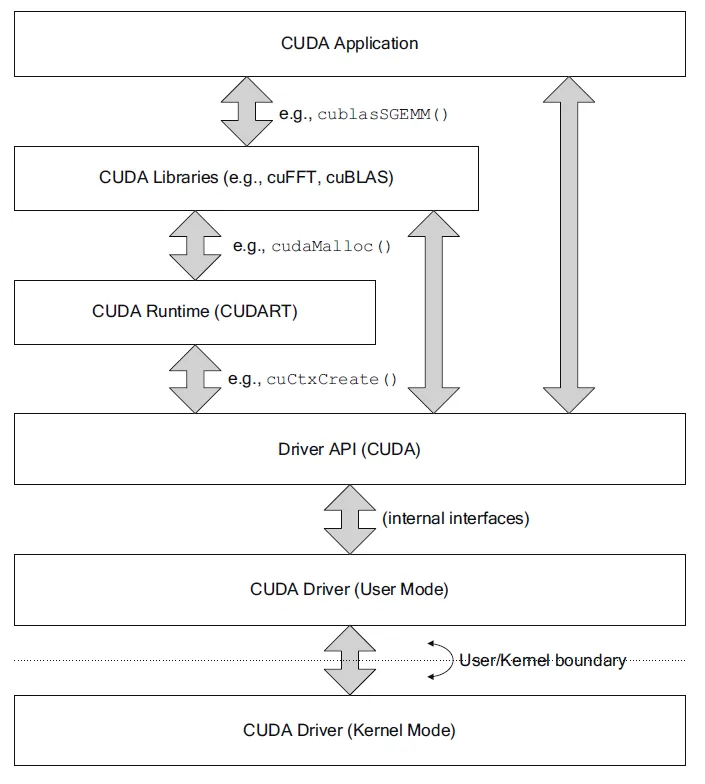
Khái niệm: Lệnh gọi từ xa (ví dụ: rCUDA, VGL) về cơ bản là điều khiển từ xa API, truyền hướng dẫn GPU qua mạng đến máy chủ từ xa để thực thi, sau đó trả về kết quả cục bộ.
Ưu điểm:
Cho phép sử dụng GPU trên các nút không có GPU.
Về mặt lý thuyết cho phép tổng hợp tài nguyên GPU.
Nhược điểm:
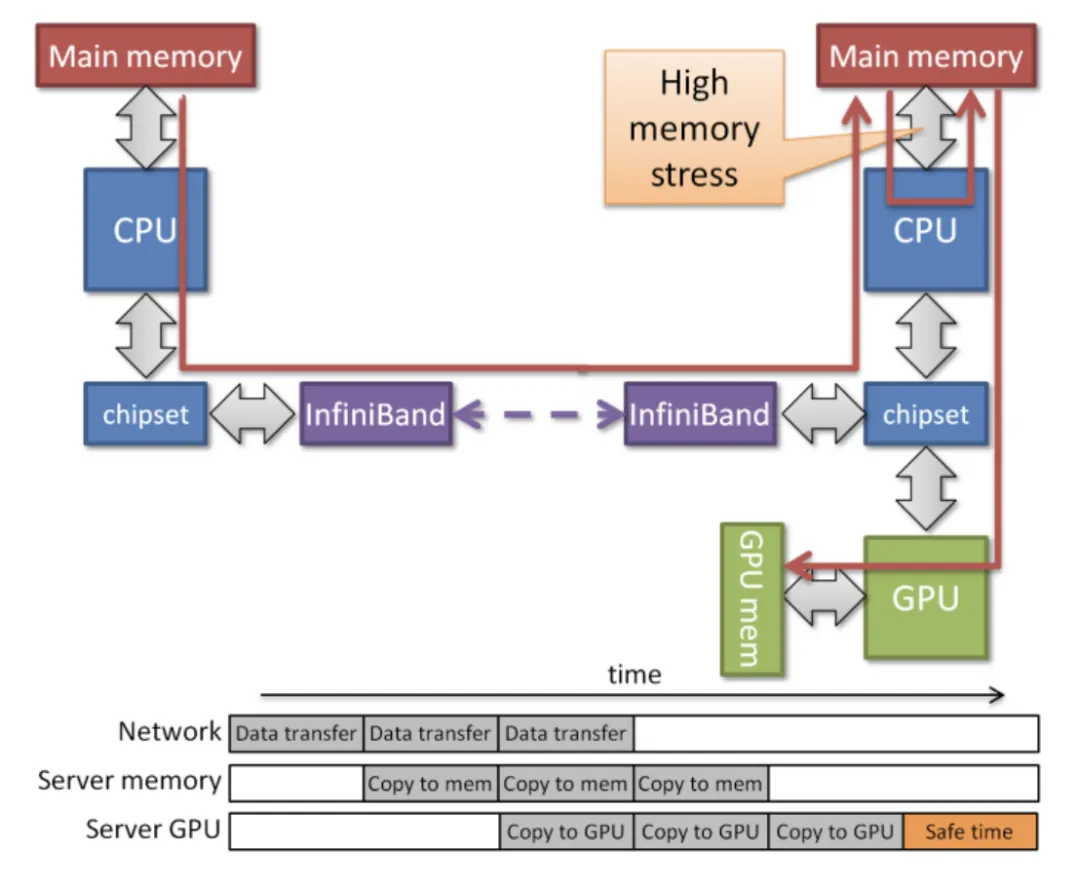
Băng thông và độ trễ mạng trở thành điểm nghẽn, giảm hiệu quả (xem bảng bên dưới để biết chi tiết).
Độ phức tạp thích ứng cao: Hoạt động của GPU yêu cầu chuyển đổi, đóng gói và giải nén, khiến nó không hiệu quả đối với các tình huống thông lượng cao.
Trường hợp sử dụng:
Các cụm phân tán có các tác vụ điện toán quy mô nhỏ, không nhạy cảm với độ trễ (ví dụ: mức sử dụng VRAM trong phạm vi vài trăm MB).
Đối với các nhu cầu hiệu suất cao, độ trễ thấp, việc gọi từ xa thường không thực tế.
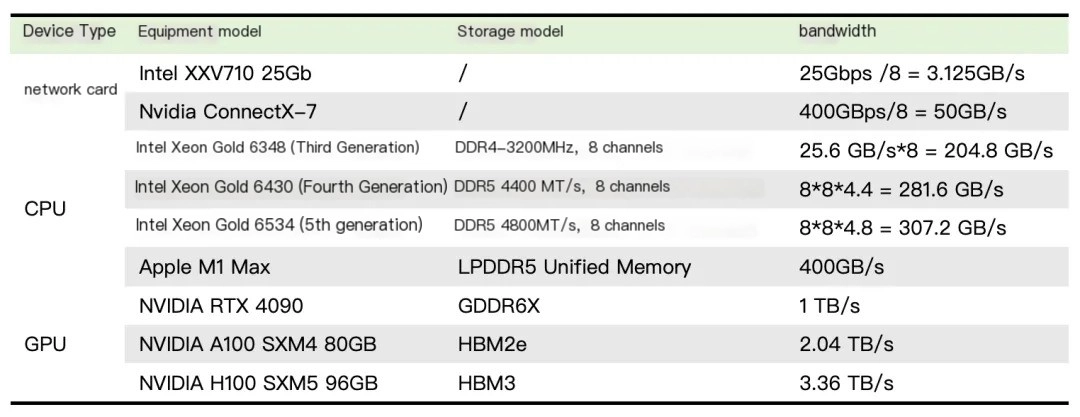
(Biểu đồ bên dưới so sánh băng thông của mạng, CPU và GPU—mặc dù không chính xác hoàn toàn nhưng nó nêu bật khoảng cách đáng kể, ngay cả với mạng 400Gb so với băng thông GPU VRAM.)
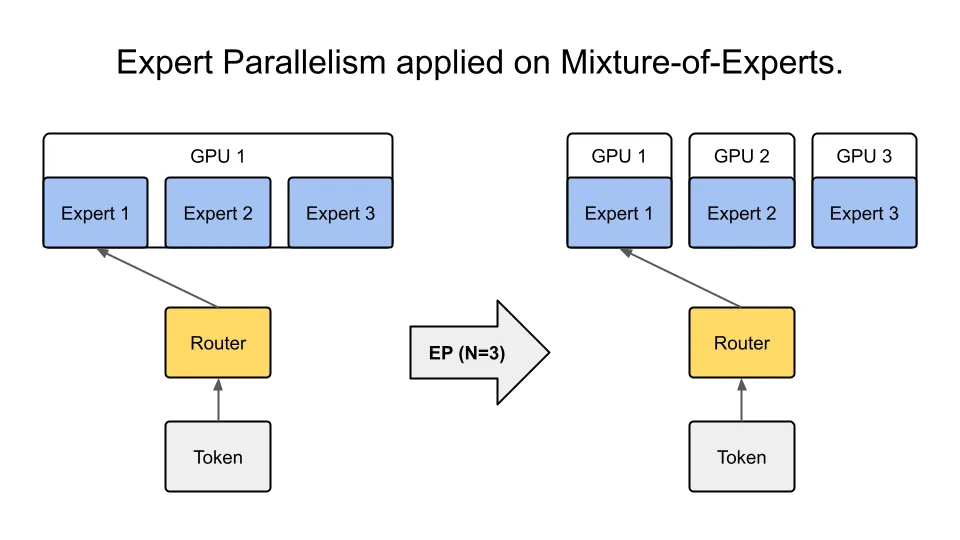
Với sự gia tăng của các mô hình ngôn ngữ lớn (LLM) như Qwen, Llama và DeepSeek, kích thước mô hình, số lượng tham số và yêu cầu VRAM đang tăng lên. Một “thẻ đơn hoặc một máy” thường không thể chứa được mô hình chứ đừng nói đến việc xử lý suy luận hoặc đào tạo quy mô lớn. Điều này đã dẫn đến các cách tiếp cận “cắt lát” và “chia sẻ” ở cấp độ mô hình, chẳng hạn như:
1. Song song Tensor, Song song đường ống, Song song chuyên gia, v.v.
Tối ưu hóa Zero Redundancy Optimizer (ZeRO) hoặc VRAM trong các khung đào tạo phân tán.
2. Phân tách GPU cho các yêu cầu nhiều người dùng trong các tình huống suy luận mô hình nhỏ.
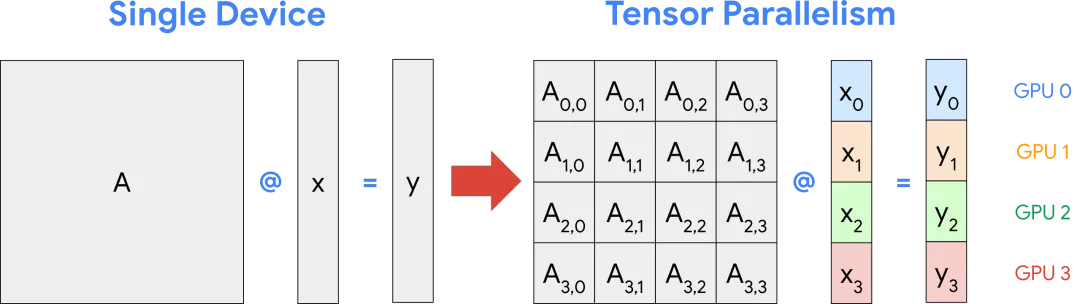
Khi triển khai các mô hình lớn, chúng thường được chia thành nhiều GPU/nút để tận dụng tổng VRAM và sức mạnh tính toán lớn hơn. Ở đây, mô hình song song trở thành “quản lý tài nguyên đa GPU thông qua khung đào tạo/suy luận phân tán”, một dạng “chia sẻ GPU” cấp cao hơn:
Đối với các model rất lớn, ngay cả việc cắt một GPU (thông qua vGPU/MIG/MPS) cũng vô ích nếu dung lượng VRAM không đủ.
Trong các kịch bản MoE (Kết hợp các chuyên gia), việc tối đa hóa thông lượng đòi hỏi nhiều GPU hơn để lập lịch và định tuyến, tận dụng tối đa sức mạnh tính toán. Tại thời điểm này, nhu cầu ảo hóa hoặc chia sẻ GPU giảm dần, chuyển trọng tâm từ phân chia VRAM sang kết nối đa GPU tốc độ cao.
1. Kịch bản mô hình siêu lớn
Nếu VRAM của một thẻ không thể xử lý khối lượng công việc thì việc phân phối song song nhiều thẻ hoặc nhiều máy là cần thiết. Ở đây, việc cắt GPU ở cấp độ phần cứng ít liên quan hơn — bạn không “chia” một thẻ vật lý cho các tác vụ mà “kết hợp” nhiều thẻ để hỗ trợ một mô hình lớn.
(Sơ đồ bên dưới minh họa tính song song tensor, chia phép toán ma trận thành các ma trận con nhỏ hơn.)
2. Ứng dụng suy luận và đào tạo trưởng thành
Trong quy trình đào tạo hoặc suy luận LLM cấp sản xuất, tính song song nhiều thẻ và lập kế hoạch hàng loạt thường được thiết lập tốt. Việc cắt GPU hoặc gọi từ xa sẽ tăng thêm độ phức tạp trong quản lý và giảm hiệu suất, khiến việc đào tạo/suy luận phân tán trên các cụm nhiều thẻ trở nên thực tế hơn.
3. Mô hình nhỏ và kịch bản thử nghiệm
Để thử nghiệm tạm thời, các ứng dụng mô hình nhỏ hoặc suy luận hàng loạt thấp, ảo hóa/chia sẻ GPU có thể tăng cường mức sử dụng. GPU cao cấp có thể chỉ sử dụng 10% khả năng tính toán hoặc VRAM của nó (ví dụ: chạy mô hình nhúng chỉ cần vài trăm MB hoặc GB) và việc cắt lát có thể cải thiện hiệu quả một cách hiệu quả.
Lệnh gọi từ xa có thể phù hợp với việc chia sẻ nội bộ cụm đơn giản, nhưng đối với các tác vụ nhạy cảm với độ trễ và băng thông như suy luận/đào tạo LLM, các lệnh gọi GPU nối mạng quy mô lớn là không thực tế.
Môi trường sản xuất thường tránh lệnh gọi từ xa để đảm bảo độ trễ suy luận thấp và giảm thiểu chi phí hoạt động, thay vào đó chọn truy cập GPU trực tiếp (toàn bộ thẻ hoặc cắt lát). Độ trễ liên lạc từ các cuộc gọi từ xa ảnh hưởng đáng kể đến thông lượng và khả năng phản hồi.
Khi VRAM một thẻ không đủ, hãy dựa vào tính song song phân tán ở cấp mô hình (ví dụ: song song tensor, song song đường ống, MoE) để “hợp nhất” tài nguyên GPU ở cấp cao hơn, thay vì “cắt” ở cấp thẻ vật lý. Điều này tối đa hóa hiệu suất và tránh tổn thất quá mức khi chuyển đổi ngữ cảnh.
Việc gọi từ xa (ví dụ: rCUDA) không được khuyến nghị ở đây trừ khi trong mạng chuyên dụng có tốc độ cao, độ trễ thấp với nhu cầu hiệu suất thoải mái.
Đối với máy ảo, hãy cân nhắc MIG (trên A100/H100) hoặc vGPU (ví dụ: NVIDIA vGPU hoặc cGPU/qGPU nguồn mở) để chia một thẻ lớn cho nhiều tác vụ song song; đối với vùng chứa, hãy sử dụng CUDA Hook để có hạn ngạch linh hoạt nhằm cải thiện việc sử dụng tài nguyên.
Theo dõi cách ly lỗi và chi phí hiệu suất. Đối với nhu cầu QoS/ổn định cao, hãy ưu tiên MIG (cách ly tốt nhất) hoặc vGPU chính thức (nếu ngân sách cấp phép cho phép).
Đối với các tình huống cụ thể hoặc thử nghiệm, CUDA Hook/hijacking cung cấp cách triển khai linh hoạt nhất.
Việc ảo hóa GPU thông qua điều khiển từ xa API gây ra sự chậm trễ đáng kể về chi phí mạng và độ trễ tuần tự hóa. Nó chỉ đáng xem xét trong các tình huống ảo hóa phân tán hiếm gặp với độ nhạy độ trễ thấp.
Nguyên tắc hoạt động của GPU đặt ra chi phí chuyển đổi ngữ cảnh cao hơn và thách thức cách ly cao hơn so với CPU. Mặc dù tồn tại nhiều kỹ thuật khác nhau (vGPU, MPS, MIG, CUDA Hook, rCUDA), nhưng không có kỹ thuật nào hoàn thiện trên toàn cầu như ảo hóa CPU.
Đối với các mô hình và sản xuất cực lớn: Khi các mô hình có kích thước lớn (ví dụ: LLM cần VRAM/điện toán lớn), “song song nhiều thẻ/nhiều máy” là chìa khóa, trong đó mô hình tự xử lý việc cắt lát. Ảo hóa GPU cung cấp ít trợ giúp về hiệu suất hoặc nhu cầu VRAM lớn. Tài nguyên có thể được chia sẻ thông qua các dịch vụ MaaS được tư nhân hóa.
Đối với các mô hình nhỏ như nhúng hoặc sắp xếp lại: Ảo hóa/chia sẻ GPU phù hợp, với sự lựa chọn công nghệ tùy thuộc vào khả năng cách ly, chi phí, khả năng tương thích SDK và mức độ dễ vận hành. MIG hoặc vGPU chính thức cung cấp khả năng cách ly mạnh mẽ nhưng tính linh hoạt hạn chế; MPS vượt trội về khả năng song song nhưng thiếu khả năng cách ly lỗi; Việc chiếm quyền điều khiển CUDA là cách linh hoạt nhất và được áp dụng rộng rãi.
Gọi từ xa (từ xa API): Nói chung không nên dùng cho các tình huống hiệu suất cao trừ khi độ trễ mạng có thể kiểm soát được và khối lượng công việc nhỏ.
Do đó, đối với LLM quy mô lớn (đặc biệt là với các tham số lớn), cách tốt nhất là phân phối các mô hình song song (ví dụ: song song tensor hoặc đường ống) để "chia sẻ" và "phân bổ" tính toán, thay vì ảo hóa các thẻ đơn lẻ. Đối với các mô hình nhỏ hoặc thử nghiệm nhiều người dùng, ảo hóa hoặc cắt GPU có thể tăng cường mức sử dụng thẻ đơn. Cách tiếp cận này hợp lý, dựa trên bằng chứng và có tính chiến lược.
Nhưng làm cách nào chúng ta có thể cải thiện hơn nữa hiệu suất GPU và tối đa hóa thông lượng với nguồn lực hạn chế? Nếu bạn quan tâm, chúng tôi sẽ đi sâu hơn vào chủ đề này trong các cuộc thảo luận trong tương lai.
 2025-02-11
2024-12-12
2025-02-11
2024-12-12